
La popularidad de la ciencia de los datos atrae a muchas personas de una amplia gama de profesiones para hacer un cambio de carrera con el objetivo de convertirse en un científico de datos.
A pesar de la gran demanda de científicos de datos, es una tarea muy difícil encontrar tu primer trabajo. A menos que tengas una sólida experiencia laboral previa, las entrevistas son el lugar donde puedes mostrar tus habilidades e impresionar a tu potencial empleador.
La ciencia de los datos es un campo interdisciplinar que abarca una amplia gama de temas y conceptos. Por ello, el número de preguntas que te pueden hacer en una entrevista es muy elevado.
Sin embargo, hay algunas preguntas sobre los fundamentos de la ciencia de los datos y el aprendizaje automático. Éstas son las que no debes perderte. En este artículo, repasaremos 10 preguntas que probablemente se hagan en una entrevista a un científico de datos.
Las preguntas están agrupadas en 3 categorías principales que son aprendizaje automático, Python y SQL. Intentaré dar una breve respuesta a cada pregunta. Sin embargo, sugiero leer o estudiar cada una con más detalle después.
Aprendizaje automático
A pesar de la gran demanda de científicos de datos, es una tarea muy difícil encontrar tu primer trabajo. A menos que tengas una sólida experiencia laboral previa, las entrevistas son el lugar donde puedes mostrar tus habilidades e impresionar a tu potencial empleador.
La ciencia de los datos es un campo interdisciplinar que abarca una amplia gama de temas y conceptos. Por ello, el número de preguntas que te pueden hacer en una entrevista es muy elevado.
Sin embargo, hay algunas preguntas sobre los fundamentos de la ciencia de los datos y el aprendizaje automático. Éstas son las que no debes perderte. En este artículo, repasaremos 10 preguntas que probablemente se hagan en una entrevista a un científico de datos.
Las preguntas están agrupadas en 3 categorías principales que son aprendizaje automático, Python y SQL. Intentaré dar una breve respuesta a cada pregunta. Sin embargo, sugiero leer o estudiar cada una con más detalle después.
Aprendizaje automático
1. ¿Qué es el overfitting (sobreajuste)?
El sobreajuste en el aprendizaje automático se produce cuando el modelo no está bien generalizado. El modelo se centra demasiado en el conjunto de entrenamiento. Capta muchos detalles o incluso ruido en el conjunto de entrenamiento. Por lo tanto, no logra captar la tendencia general o las relaciones en los datos. Si un modelo es demasiado complejo en comparación con los datos, probablemente estará sobreajustado.
Un buen indicador de sobreajuste es la gran diferencia entre la precisión de los conjuntos de entrenamiento y de prueba. Los modelos sobreajustados suelen tener una precisión muy alta en el conjunto de entrenamiento, pero la precisión de la prueba suele ser impredecible y mucho más baja que la de entrenamiento.
2. ¿Cómo se puede reducir el overfitting?
Podemos reducir el sobreajuste haciendo que el modelo sea más generalizado, lo que significa que debe centrarse más en la tendencia general que en los detalles específicos.
Si es posible, recoger más datos es una forma eficaz de reducir el sobreajuste. Le darás más jugo al modelo para que tenga más material del que aprender. Los datos siempre son valiosos, especialmente para los modelos de aprendizaje automático.
Otro método para reducir la sobreadaptación es reducir la complejidad del modelo. Si un modelo es demasiado complejo para una tarea determinada, es probable que se produzca un sobreajuste. En estos casos, debemos buscar modelos más sencillos.
3. ¿Qué es la regularización?
Hemos mencionado que la principal razón del sobreajuste es que un modelo sea más complejo de lo necesario. La regularización es un método para reducir la complejidad del modelo.
Lo hace penalizando los términos más altos del modelo. Con la adición de un término de regularización, el modelo intenta minimizar tanto la pérdida como la complejidad.
Los dos tipos principales de regularización son L1 y L2. La regularización L1 resta una pequeña cantidad de los pesos de las características no informativas en cada iteración. Así, hace que estos pesos se conviertan finalmente en cero.
Por otro lado, la regularización L2 elimina un pequeño porcentaje de los pesos en cada iteración. Estos pesos se acercarán a cero, pero nunca llegarán a ser 0.
4. ¿Cuál es la diferencia entre clasificación y agrupación?
Ambas son tareas de aprendizaje automático. La clasificación es una tarea de aprendizaje supervisado, por lo que tenemos observaciones etiquetadas (es decir, puntos de datos). Entrenamos un modelo con datos etiquetados y esperamos que prediga las etiquetas de los nuevos datos.
Por ejemplo, la detección de correos electrónicos no deseados es una tarea de clasificación. Proporcionamos un modelo con varios correos electrónicos marcados como spam o no spam. Una vez entrenado el modelo con esos correos, evaluará los nuevos correos de forma adecuada.
La agrupación es una tarea de aprendizaje no supervisada, por lo que las observaciones no tienen etiquetas. Se espera que el modelo evalúe las observaciones y las agrupe en clusters. Las observaciones similares se colocan en el mismo clúster.
En el caso óptimo, las observaciones del mismo clúster están lo más cerca posible unas de otras y los diferentes clústeres están lo más separados posible. Un ejemplo de tarea de clustering sería agrupar a los clientes en función de su comportamiento de compra.
Python
Las estructuras de datos incorporadas son de crucial importancia. Por lo tanto, debes estar familiarizado con lo que son y cómo interactuar con ellas. Lista, diccionario, conjunto y tupla son las 4 principales estructuras de datos incorporadas en Python.
5. ¿Cuál es la diferencia entre listas y tuplas?
La principal diferencia entre las listas y las tuplas es la mutabilidad. Las listas son mutables, por lo que podemos manipularlas añadiendo o eliminando elementos.
mylist = [1,2,3] mylist.append(4) mylist.remove(1) print(mylist) [2,3,4]
En cambio, las tuplas son inmutables. Aunque podemos acceder a cada elemento de una tupla, no podemos modificar su contenido.
mytuple = (1,2,3) mytuple.append(4) AttributeError: 'tuple' object has no attribute 'append'
Un punto importante a mencionar aquí es que aunque las tuplas son inmutables, pueden contener elementos mutables como listas o conjuntos.
mytuple = (1,2,["a","b","c"]) mytuple[2] ['a', 'b', 'c'] mytuple[2][0] = ["A"] print(mytuple) (1, 2, [['A'], 'b', 'c'])
6. ¿Cuál es la diferencia entre listas y sets?
Hagamos un ejemplo para demostrar la principal diferencia entre listas y conjuntos.
text = "Python is awesome!"
mylist = list(text)
myset = set(text)
print(mylist)
['P', 'y', 't', 'h', 'o', 'n', ' ', 'i', 's', ' ', 'a', 'w', 'e', 's', 'o', 'm', 'e', '!']
print(myset)
{'t', ' ', 'i', 'e', 'm', 'P', '!', 'y', 'o', 'h', 'n', 'a', 's', 'w'}Como vemos en los objetos resultantes, la lista contiene todos los caracteres de la cadena mientras que el conjunto sólo contiene valores únicos.
Otra diferencia es que los caracteres de la lista están ordenados según su ubicación en la cadena. Sin embargo, los caracteres del conjunto no están ordenados.
A continuación se muestra una tabla que resume las principales características de las listas, las tuplas y los conjuntos.
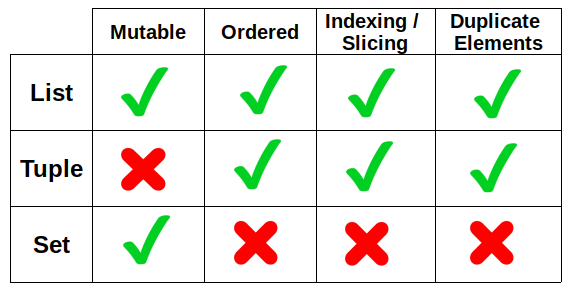
(image by author)
7. ¿Qué es un diccionario y cuáles son las características importantes de los diccionarios?
Un diccionario en Python es una colección de pares clave-valor. Es similar a una lista en el sentido de que cada elemento de una lista tiene un índice asociado que empieza por 0.
mylist = ["a", "b", "c"] mylist[1] "b"
En un diccionario, las claves son el índice. Así, podemos acceder a un valor utilizando su clave.
mydict = {"John": 24, "Jane": 26, "Ashley": 22}
mydict["Jane"]
26Las claves de un diccionario son únicas, lo que tiene sentido porque actúan como una dirección para los valores.
SQL
SQL es una habilidad extremadamente importante para los científicos de datos. Hay un gran número de empresas que almacenan sus datos en una base de datos relacional. SQL es lo que se necesita para interactuar con las bases de datos relacionales.
Es probable que te hagan una pregunta que implique escribir una consulta para realizar una tarea específica. También es posible que te hagan una pregunta sobre conocimientos generales de bases de datos.
8. Ejemplo de Consulta #1
Consider we have a sales table that contains daily sales quantities of products.
SELECT TOP 10 * FROM SalesTable
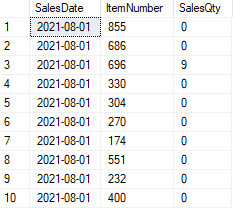
(image by author)
Encuentre las 5 semanas más importantes en términos de cantidades totales de ventas semanales.
SELECT TOP 5 CONCAT(YEAR(SalesDate), DATEPART(WEEK, SalesDate)) AS YearWeek, SUM(SalesQty) AS TotalWeeklySales FROM SalesTable GROUP BY CONCAT(YEAR(SalesDate), DATEPART(WEEK, SalesDate)) ORDER BY TotalWeeklySales DESC
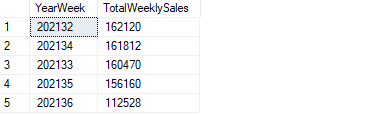
(image by author)
Primero extraemos la información del año y la semana de la columna de la fecha y luego la utilizamos en la agregación. La función de suma se utiliza para calcular las cantidades totales de ventas.
9. Ejemplo de consulta #2
En la misma tabla de ventas, encuentre el número de artículos únicos que se venden cada mes.
SELECT MONTH(SalesDate) AS Month, COUNT(DISTINCT(ItemNumber)) AS ItemCount FROM SalesTable GROUP BY MONTH(SalesDate) Month ItemCount 1 9 1021 2 8 1021
10. ¿Qué es la normalización y la desnormalización en una base de datos?
Estos términos están relacionados con el diseño del esquema de la base de datos. La normalización y la desnormalización tienen como objetivo optimizar diferentes métricas.
El objetivo de la normalización es reducir la redundancia e inconsistencia de los datos aumentando el número de tablas. Por otro lado, la desnormalización tiene como objetivo acelerar la ejecución de la consulta. La desnormalización disminuye el número de tablas, pero al mismo tiempo añade cierta redundancia.
Conclusión
Convertirse en un científico de datos es una tarea difícil. Requiere tiempo, esfuerzo y dedicación. Sin tener experiencia laboral previa, el proceso se hace más difícil.
Las entrevistas son muy importantes para demostrar tus habilidades. En este artículo, hemos cubierto 10 preguntas que es probable que te encuentres en una entrevista de científico de datos.
Gracias por leerlo. Por favor, hágame saber si tiene algún comentario.







