
Predicción del precio de los coches usados usando Machine Learning
En este artículo, echaremos un vistazo al reciente proyecto que completé, donde predije los precios de los coches usados en base a una serie de factores. Encontré el conjunto de datos de Kaggle.
Este proyecto es especial ya que intenté muchas cosas diferentes y luego terminé en el notebook que se incluye como parte del repositorio. Explicaré todos y cada uno de los pasos que pensé y cómo resultó ser. El repositorio con el código está abajo:
kb22/Used-Car-Price-Prediction
En este artículo, echaremos un vistazo al reciente proyecto que completé, donde predije los precios de los coches usados en base a una serie de factores. Encontré el conjunto de datos de Kaggle.
Este proyecto es especial ya que intenté muchas cosas diferentes y luego terminé en el notebook que se incluye como parte del repositorio. Explicaré todos y cada uno de los pasos que pensé y cómo resultó ser. El repositorio con el código está abajo:
kb22/Used-Car-Price-Prediction
Demasiado tiempo, no leerá
Aquí está el meollo del artículo:
- La creación de nuevas características podría ser útil, por ejemplo, creé la característica Manufacturer a partir del Name
- Pruebe diferentes enfoques para manejar la misma columna. La columna Year (año) cuando se usa directamente produce malos resultados, así que en su lugar usé la edad de cada coche derivado de ella, lo cual fue mucho más útil. New_Price se llenó primero con valores promedio basados en el Manufacturer pero no fue útil, así que dejé la columna en la segunda iteración.
- Las columnas que parecen irrelevantes deben ser eliminadas. Dejé Index (índice), Location (ubicación), Name (nombre) y New_Price.
- La creación de dummies requiere el manejo de las columnas que faltan en los datos de prueba.
- Juega con los parámetros del modelo ML ya que puede ser útil. El parámetro n_estimator en RandomForestRegressor mejoró el r2_score cuando puse el valor en 100. También intenté 1000, pero sólo tomó mucho más tiempo sin ninguna mejora notable.
Si todavía quieres los detalles completos, ¡sigue leyendo!
Importar Librerias
import datetime import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import StandardScaler from sklearn.metrics import r2_score
Leer Conjunto De Datos
El conjunto de datos original de Kaggle tenía dos archivos: train-data.csv y test-data.csv. Sin embargo, las etiquetas de salida final del archivo test-data.csv no se dieron y por lo tanto, nunca sería capaz de probar mi modelo. Por lo tanto, decidí trabajar con el archivo train-data.csv y renombrarlo como dataset.csv dentro de la carpeta data.
dataset = pd.read_csv("data/dataset.csv")
dataset.head(5)
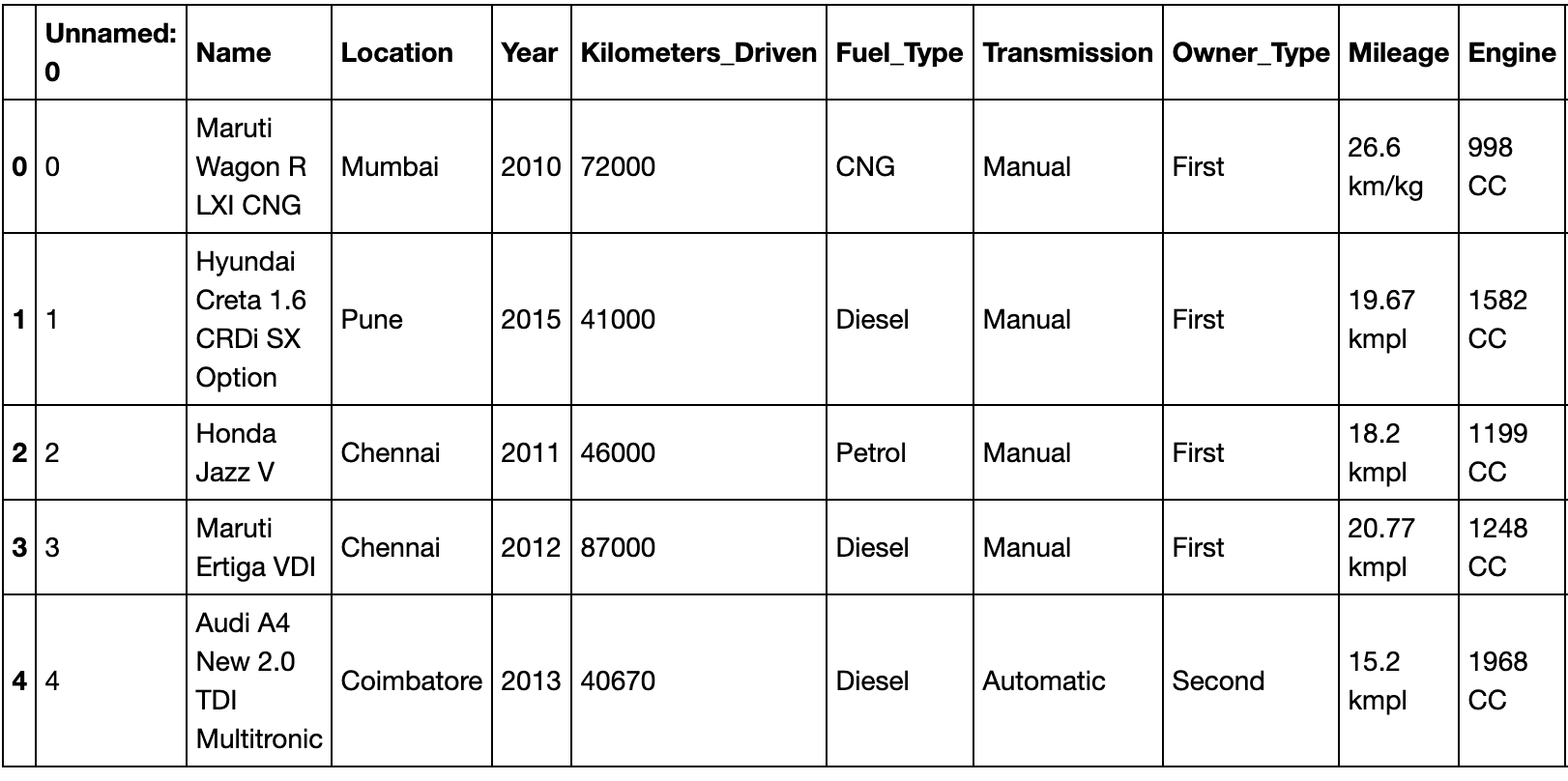
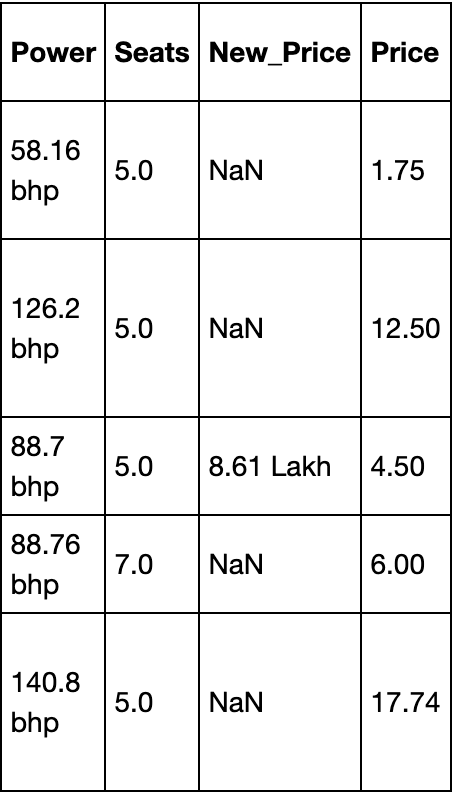
Luego dividí el conjunto de datos en un 70% de entrenamiento y un 30% de datos de prueba.
X_train, X_test, y_train, y_test = train_test_split(dataset.iloc[:, :-1],
dataset.iloc[:, -1],
test_size = 0.3,
random_state = 42)
X_train.info()
## Output
# <class 'pandas.core.frame.DataFrame'>
# Int64Index: 4213 entries, 4201 to 860
# Data columns (total 13 columns):
# Unnamed: 0 4213 non-null int64
# Name 4213 non-null object
# Location 4213 non-null object
# Year 4213 non-null int64
# Kilometers_Driven 4213 non-null int64
# Fuel_Type 4213 non-null object
# Transmission 4213 non-null object
# Owner_Type 4213 non-null object
# Mileage 4212 non-null object
# Engine 4189 non-null object
# Power 4189 non-null object
# Seats 4185 non-null float64
# New_Price 580 non-null object
# dtypes: float64(1), int64(3), object(9)
# memory usage: 460.8+ KBYo saco la información de los datos de entrenamiento para ver cómo se ven los datos. Encontramos que algunas columnas como Mileage, Engine, Power y Seats tienen unos pocos valores nulos mientras que New_Price tiene la mayoría de sus valores perdidos. Para obtener una mejor esencia de lo que cada columna representa realmente, podemos echar un vistazo al tablero de Kaggle que tiene la descripción de los datos.

El conjunto de datos está ahora cargado y sabemos lo que significa cada columna. Ahora es el momento de hacer un análisis exploratorio. Tengan en cuenta que siempre trabajaré con la parte de entrenamiento y luego transformaré la parte de prueba basada sólo en la parte de entrenamiento.
Análisis exploratorio de datos
Aquí, exploraremos cada una de las columnas de arriba y discutiremos su relevancia.
Index
La primera columna del conjunto de datos no tiene nombre. En realidad es sólo un índice para cada fila y por lo tanto, podemos eliminar esta columna con seguridad.
X_train = X_train.iloc[:, 1:] X_test = X_test.iloc[:, 1:]
Name
La columna Name (Nombre) define el nombre de cada coche. Pensé que el nombre del auto no tendría un gran impacto pero el fabricante del auto sí. Por ejemplo, si generalmente la gente encuentra que Maruti produce autos confiables, sus valores de reventa deberían ser más altos. Por lo tanto, decidí extraer el fabricante de cada Name. La primera palabra de cada Name es el fabricante.
make_train = X_train["Name"].str.split(" ", expand = True)
make_test = X_test["Name"].str.split(" ", expand = True)
X_train["Manufacturer"] = make_train[0]
X_test["Manufacturer"] = make_test[0]También vamos a graficar y ver el conteo de cada auto basado en el fabricante.
plt.figure(figsize = (12, 8))
plot = sns.countplot(x = 'Manufacturer', data = X_train)
plt.xticks(rotation = 90)
for p in plot.patches:
plot.annotate(p.get_height(),
(p.get_x() + p.get_width() / 2.0,
p.get_height()),
ha = 'center',
va = 'center',
xytext = (0, 5),
textcoords = 'offset points')
plt.title("Count of cars based on manufacturers")
plt.xlabel("Manufacturer")
plt.ylabel("Count of cars")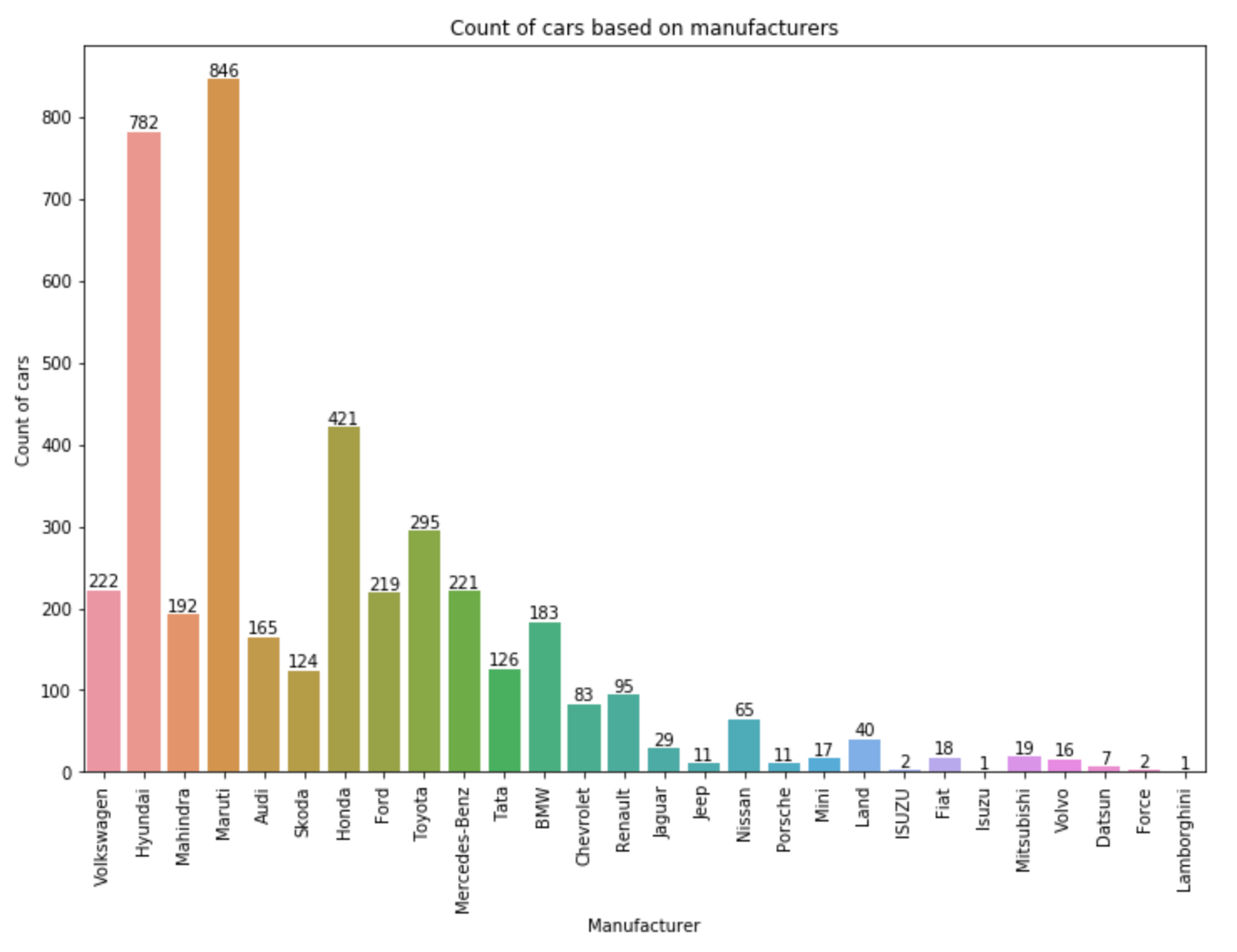
Como podemos ver en el gráfico de arriba, Maruti tiene el máximo número de coches y Lamborghini tiene el mínimo número de coches en todos los datos de entrenamiento. Además, no necesito la columna del nombre, así que la descarté.
X_train.drop("Name", axis = 1, inplace = True)
X_test.drop("Name", axis = 1, inplace = True)Location
Inicialmente intenté usar Location, pero me llevó a muchas columnas calientes sin contribuir mucho a la ayuda de la predicción. Esto significa que la localización de la venta tiene un efecto casi insignificante en el precio final de reventa de un coche. Por lo tanto, decidí eliminar esta columna.
X_train.drop("Location", axis = 1, inplace = True)
X_test.drop("Location", axis = 1, inplace = True)Year
Inicialmente mantuve a Year tal como está para definir la marca del modelo. Pero más tarde me di cuenta de que más que el año, es la edad del coche lo que tiene un efecto en el valor de reventa. Así que, siguiendo las indicaciones de Kaggle, decidí sustituir Year por la edad del coche restando el año del año actual.
curr_time = datetime.datetime.now() X_train['Year'] = X_train['Year'].apply(lambda x : curr_time.year - x) X_test['Year'] = X_test['Year'].apply(lambda x : curr_time.year - x)
Fuel_Type, Transmission, and Owner_Type
Todas estas columnas son columnas categóricas. Por lo tanto, crearé columnas dummy para cada una de estas columnas y las usaré para la predicción.
Kilometers_Driven
X_train["Kilometers_Driven"] ## Output # 4201 77000 # 4383 19947 # 1779 70963 # 4020 115195 # 3248 58752 # ... # 3772 27000 # 5191 9000 # 5226 140000 # 5390 76414 # 860 98000 # Name: Kilometers_Driven, Length: 4213, dtype: int64
La salida de datos muestra los valores altos que existen en la columna. Deberíamos escalar los datos, ya que de lo contrario las columnas como Kilometers_Driven pueden tener un efecto mucho más fuerte en la predicción que otras columnas.
Mileage
Mileage define el kilometraje del coche. Sin embargo, las unidades de kilometraje varían según el tipo de motor, por ejemplo, algunas son por Kg. mientras que otras son por L. Pero para este caso, las consideraremos equivalentes y sólo extraeremos los números de esta columna.
mileage_train = X_train["Mileage"].str.split(" ", expand = True)
mileage_test = X_test["Mileage"].str.split(" ", expand = True)
X_train["Mileage"] = pd.to_numeric(mileage_train[0], errors = 'coerce')
X_test["Mileage"] = pd.to_numeric(mileage_test[0], errors = 'coerce')Como hemos comprobado antes, a la columna de kilometraje le faltaban algunos valores, así que comprobémoslos y actualicemos los valores nulos con la media de la columna.
print(sum(X_train["Mileage"].isnull()))
print(sum(X_test["Mileage"].isnull()))
## Output
# 1
# 1
X_train["Mileage"].fillna(X_train["Mileage"].astype("float64").mean(), inplace = True)
X_test["Mileage"].fillna(X_train["Mileage"].astype("float64").mean(), inplace = True)Engine, Power y Seats
Los valores de la Engine están definidos en CC, así que necesito eliminar CC de los datos. Del mismo modo, Power tiene bhp, así que quitaré bhp de ella. Además, como faltan valores en los tres, los reemplazaré de nuevo con la media como hice con el Mileage.
Utilizo pd.to_numeric() como maneja los valores nulos y no produce errores al convertir de cadena a numérico (int o float).
Utilizo pd.to_numeric() como maneja los valores nulos y no produce errores al convertir de cadena a numérico (int o float).
cc_train = X_train["Engine"].str.split(" ", expand = True)
cc_test = X_test["Engine"].str.split(" ", expand = True)
X_train["Engine"] = pd.to_numeric(cc_train[0], errors = 'coerce')
X_test["Engine"] = pd.to_numeric(cc_test[0], errors = 'coerce')
bhp_train = X_train["Power"].str.split(" ", expand = True)
bhp_test = X_test["Power"].str.split(" ", expand = True)
X_train["Power"] = pd.to_numeric(bhp_train[0], errors = 'coerce')
X_test["Power"] = pd.to_numeric(bhp_test[0], errors = 'coerce')
X_train["Engine"].fillna(X_train["Engine"].astype("float64").mean(), inplace = True)
X_test["Engine"].fillna(X_train["Engine"].astype("float64").mean(), inplace = True)
X_train["Power"].fillna(X_train["Power"].astype("float64").mean(), inplace = True)
X_test["Power"].fillna(X_train["Power"].astype("float64").mean(), inplace = True)
X_train["Seats"].fillna(X_train["Seats"].astype("float64").mean(), inplace = True)
X_test["Seats"].fillna(X_train["Seats"].astype("float64").mean(), inplace = True)New_Price
La mayoría de los valores de la columna están perdidos. Inicialmente decidí llenarlos. Llenaría el valor medio basado en el fabricante. Por ejemplo, para Ford, tomaría todos los valores que están presentes, tomaría su media y luego reemplazaría todos los valores nulos de New_Price para Ford con esa media. Sin embargo, esto todavía deja fuera algunos valores nulos. Entonces llenaría estos valores nulos con la media de todos los valores de la columna. Lo mismo se repitió para los datos de la prueba también.
Sin embargo, este enfoque no fue realmente exitoso. Intenté ejecutar el Random Forest Regressor en él y los resultados fueron valores muy pequeños de r2_score. A continuación, decidí que simplemente dejaría la columna y los valores de r2_score mejoraron significativamente.
Sin embargo, este enfoque no fue realmente exitoso. Intenté ejecutar el Random Forest Regressor en él y los resultados fueron valores muy pequeños de r2_score. A continuación, decidí que simplemente dejaría la columna y los valores de r2_score mejoraron significativamente.
X_train.drop(["New_Price"], axis = 1, inplace = True) X_test.drop(["New_Price"], axis = 1, inplace = True)
Procesamienmto de Datos
Aquí, crearé columnas ficticias usando pd.get_dummies para todas las variables categóricas.
X_train = pd.get_dummies(X_train,
columns = ["Manufacturer", "Fuel_Type", "Transmission", "Owner_Type"],
drop_first = True)
X_test = pd.get_dummies(X_test,
columns = ["Manufacturer", "Fuel_Type", "Transmission", "Owner_Type"],
drop_first = True)Sin embargo, es muy posible que debido a la falta de todos los tipos de datos de prueba, puedan faltar columnas. Entendámoslo con un ejemplo. Por ejemplo, en la columna Transmission, los datos de entrenamiento incluyen Manual y Automatic, por lo que los maniquíes serían como Transmission_Manual y Transmission_Automatic. Pero, ¿qué pasa si los datos de la prueba sólo tienen valor Manual y no tienen valor Automatic? En tal caso, dummies sólo llevarían a Transmission_Manual. Esto dejaría el conjunto de datos de la prueba una columna más corta en comparación con los datos de entrenamiento y la predicción no funcionaría. Para manejar esto, creamos columnas en los datos de prueba que faltan y las llenamos con cero. Finalmente, ordenamos los datos de la prueba como los datos del entrenamiento.
missing_cols = set(X_train.columns) - set(X_test.columns)
for col in missing_cols:
X_test[col] = 0
X_test = X_test[X_train.columns]Por último, escalaría los datos
standardScaler = StandardScaler() standardScaler.fit(X_train) X_train = standardScaler.transform(X_train) X_test = standardScaler.transform(X_test)
Entrenamiento y Prediccion
Crearé una regresión lineal y un modelo de bosque aleatorio para entrenar los datos y comparar los valores de r2_score para seleccionar la mejor elección.
Crearé una regresión lineal y un modelo de bosque aleatorio para entrenar los datos y comparar los valores de r2_score para seleccionar la mejor elección.
linearRegression = LinearRegression() linearRegression.fit(X_train, y_train) y_pred = linearRegression.predict(X_test) r2_score(y_test, y_pred) rf = RandomForestRegressor(n_estimators = 100) rf.fit(X_train, y_train) y_pred = rf.predict(X_test) r2_score(y_test, y_pred)
Consigo el r2_score para Regresión Lineal como 0.70 y para Bosque Aleatorio como 0.88. Por lo tanto, Random Forest se desempeñó muy bien en los datos de la prueba.
Conclusión
En este artículo, vimos cómo abordar un problema de Machine Learning en la vida real y cómo podríamos ajustar las características en función de su relevancia y de la información que proporcionan.




