
Los fundadores de startups o empresas, los directivos o los tomadores de decisiones suelen afirmar que son "ricos en datos pero pobres en información". Esta afirmación es en muchos casos sólo parcialmente correcta porque oculta una idea errónea sobre el ciclo de vida de los datos y de la ciencia de datos. El hecho de estar repleto de datos pero con poca información sugiere que las fuentes de datos no explotadas anteriormente están esperando ser explotadas y utilizadas.
Es muy improbable que alguna organización reúna datos sin un propósito particular. En la mayoría de los casos, los datos se reúnen para gestionar los procesos operacionales. La reunión de datos sin un propósito determinado es un desperdicio de recursos. En muchas empresas, una vez que los datos se utilizan, se almacenan y se convierten en "datos oscuros".
Debido a que casi todos los procesos operacionales se registran electrónicamente, los datos ahora están en todas partes. Los gerentes se preguntan con razón qué hacer con esta información después de ser archivada. Un enfoque estratégico de la ciencia de datos ayudaría a una organización a desentrañar el valor no explotado de estos almacenes de datos para comprender mejor su contexto estratégico y operacional.
La evolución para convertirse en una organización basada en datos comienza con la recolección de datos generados durante los procesos operacionales. El siguiente paso consiste en describir estos datos mediante técnicas exploratorias como las visualizaciones y la estadística, que es el dominio del reporte tradicional en los negocios (o lo que se llama hoy en día Business Intelligence) el cual brinda insights para la toma de decisiones.

Una vez explorados y comprendidos los datos, las organizaciones pueden diagnosticar los procesos comerciales para comprender las relaciones causales y lógicas entre las variables. La penúltima fase consiste en utilizar el conocimiento del pasado y sus conexiones causales y lógicas para predecir posibles futuros y construir el futuro deseado. La etapa final del viaje de la ciencia de datos es una situación en la que los datos se utilizan para prescribir las operaciones cotidianas
Este proceso no es un viaje de izquierda a derecha, eventualmente aterrizando en un lugar donde los algoritmos controlan nuestro destino, y el resto se vuelve menos crítico. Este proceso guía la estrategia de la ciencia de datos hacia este punto, pero forma una estricta jerarquía.
Antes de que los algoritmos puedan decidir algo de forma independiente, necesitas ser capaz de predecir el futuro inmediato. Para predecir el futuro, necesitas tener una buena comprensión de las estadísticas descriptivas para diagnosticar un proceso de negocios. Por último, el principio Garbage-In-Garbage-Out (GIGO) exige que el análisis sólo sea posible si comprendemos los datos recogidos.
Hacia una organización basada en datos
El proceso que acabamos de ver proporciona un mapa estratégico para las organizaciones que tratan de basarse más en los datos. Cada uno de los pasos del proceso es igualmente importante para el siguiente nivel porque estos niveles más altos de complejidad no pueden lograrse sin abarcar los niveles más bajos. El aspecto más importante del proceso de la ciencia de datos es que resume un enfoque evolutivo para convertirse en una organización impulsada por los datos.
A medida que una organización evoluciona hacia formas más complejas de la ciencia de datos, las primeras etapas no se convierten en apéndices vestigiales, sino que siguen siendo una parte integral de la estrategia de la ciencia de los datos. Todas las partes de este modelo tienen el mismo valor relativo.
Sin embargo, ser impulsado por los datos es más que un proceso de creciente complejidad. La gestión basada en la evidencia requiere que las personas dentro de la organización sean conocedoras de los datos y trabajen juntas hacia un objetivo común.
El aspecto sistemático de la ciencia de datos requiere un proceso formalizado para garantizar resultados sólidos. La creciente complejidad de los métodos analíticos también requiere de una inversión en mejores instrumentos e infraestructura de datos.
Existen muchos aspectos técnicos que hay que tener en cuenta al aplicar la ciencia de datos en una organización. Sin embargo, el mero hecho de centrarse en los tecnicismos del análisis de datos no es suficiente para crear valor para una organización. Un administrador de ciencia de datos necesita administrar personas, sistemas y procesos para desarrollar una organización basada en datos.
Los responsables de la toma de decisiones a veces ignoran incluso las visualizaciones más útiles y estéticas, incluso cuando el análisis es sólido. La ciencia de datos que utiliza las mejores prácticas, es sólo el punto de partida para crear una organización basada en valor (value-driven organization). Un aspecto crítico para asegurar que los administradores utilicen los resultados es fomentar una cultura basada en los datos, lo que requiere administrar a las personas.
Para permitir que la ciencia de datos florezca, la organización necesita tener un conjunto bien establecido de sistemas informáticos para almacenar y analizar los datos y presentar los resultados. Se dispone de una amplia gama de herramientas de ciencia de datos, cada una de las cuales desempeña un papel diferente en la cadena de valor del análisis.
Cada proyecto de ciencia de datos comienza con una definición del problema que se traduce en datos y código para definir una solución. Este problema se inyecta en el vórtice de datos hasta que se encuentra una solución. El proceso de la ciencia de datos discute el flujo de trabajo de la creación de “productos de datos”.
Los tres aspectos para convertirse en una organización basada en datos y para implementar estratégicamente la ciencia de datos se requiere alinear a:
- Las personas
- Los sistemas y
- Los procesos
Esto con el fin de optimizar el valor que se puede extraer de la información disponible.
1- Las Personas
Cuando se habla de las personas en una organización basada en datos, no debemos mencionar solamente a los especialistas que crean los productos de datos. Los miembros del equipo de ciencias de datos poseen las competencias que se muestran en el siguiente diagrama

Estas personas que son claramente técnicas deben ser capaces de comunicar los resultados de su trabajo a sus colegas o clientes y convencerlos de que apliquen los hallazgos.
La ciencia de datos no sólo ocurre exclusivamente dentro del equipo especializado. Cada proyecto de datos tiene un cliente interno o externo que tiene un problema que necesita una respuesta. El equipo de ciencia de datos y los usuarios de sus productos trabajan juntos para mejorar la organización.
Esto implica que un científico de datos necesita entender los principios básicos del comportamiento organizacional y el manejo del cambio y ser un buen comunicador. Por el contrario, los receptores de la ciencia de datos necesitan tener suficiente conocimiento de los datos para entender cómo interpretar y utilizar los resultados.
2- Los Sistemas
Al igual que cualquier otra profesión, un científico de datos necesita un conjunto adecuado de herramientas para crear valor a partir de los datos. Hay una gran cantidad de soluciones para la ciencia de datos disponibles en el mercado, muchas de las cuales son software de código abierto. Existen herramientas especializadas para cada aspecto del flujo de trabajo de la ciencia de datos.
No hay necesidad de discutir la multitud de paquetes que están disponibles. Muchos sitios web excelentes examinan las diversas ofertas. Ofreceremos por el contrario, algunas reflexiones sobre el uso de las Excel (o cualquier otro spreadsheet) frente a la escritura de código y las plataformas de business intelligence.
Las hojas de cálculo son una herramienta versátil para analizar datos que ha proliferado en casi todos los aspectos de los negocios. Sin embargo, esta herramienta universal no es muy adecuada para emprender una ciencia de datos compleja y sofisticada. Una de las ventajas que se perciben de las hojas de cálculo es que contienen los datos, el código y la salida en un archivo conveniente. Esta conveniencia tiene un precio, ya que reduce la solidez del análisis.
Cualquiera que haya tenido alguna vez el disgusto de hacer ingeniería inversa en una hoja de cálculo entenderá las limitaciones de las hojas de cálculo. En las hojas de cálculo, no queda claro inmediatamente qué celda es el resultado de otra celda y cuáles son los datos originales.
Muchas organizaciones utilizan las hojas de cálculo como única fuente de verdad para los datos de las empresas, lo que debería evitarse si es necesario compartir la información. La mejor práctica de la ciencia de datos es separar los datos, el código y el resultado.
Como se ha mencionado anteriormente, la mejor manera de crear unicornios en la ciencia de datos es enseñar a los expertos en la materia a escribir código analítico. Escribir código con R o Python es como escribir un manual de instrucciones sobre cómo analizar datos. Cualquiera que entienda el lenguaje será capaz de saber cómo se derivan sus conclusiones.
Los modernos lenguajes de la ciencia de datos pueden generar visualizaciones con calidad de impresión y pueden producir resultados en muchos formatos, incluyendo una hoja de cálculo o una aplicación independiente.
El estándar de oro para la programación en la ciencia de datos es la programación bien documentada. Esta técnica combina el código con “pseudocódigo” (o para hacerlo más sencillo, se trata de hacer comentarios al lado del código escrito, y así explicar cómo fue creado y cuál es su función) y así permitir que el algoritmo se entienda completamente. Todos los lenguajes de programación incluyen la capacidad de agregar estos comentarios.
Cada lenguaje tiene sus propios métodos para combinar el texto con el código. RMarkdown, Jupyter Notebooks y Org Mode son sistemas populares para llevar a cabo en análisis de datos y permiten entender fácilmente esos comentarios (incluso a modo de blog post con edición de texto). Una vez que se escribe el código, con sólo pulsar un botón la máquina genera un nuevo informe con estadísticas y gráficos actualizados.
Por último, las herramientas de Business Intelligence son útiles para difundir los resultados de un proyecto de ciencia de datos, pero no son muy útiles para realizar un análisis detallado. Una plataforma como Power BI es un gran sistema para visualizar el resultado de un análisis porque proporciona formas muy flexibles de cortar y trocear los datos y visualizar los resultados. Las capacidades analíticas de la plataforma no son muy altas pero pueden ser modificadas insertando código en Python o R para complementar sus capacidades.
Lea También: ¿Por qué las competiciones en data science son importantes para las startups?
Lea También: ¿Por qué las competiciones en data science son importantes para las startups?
3- Los procesos
El proceso de creación de valor a partir de los datos sigue un flujo de trabajo iterativo que funciona desde los datos en bruto hasta un proyecto terminado.
El flujo de trabajo comienza con la definición de un problema que necesita ser resuelto como se muestra en la siguiente figura. El siguiente paso implica cargar y transformar los datos en un formato adecuado para el análisis requerido. El flujo de trabajo de la ciencia de datos contiene un bucle que consiste en la exploración, el modelado y la reflexión, que se repite hasta que el problema se resuelve o se demuestra que no tiene solución.
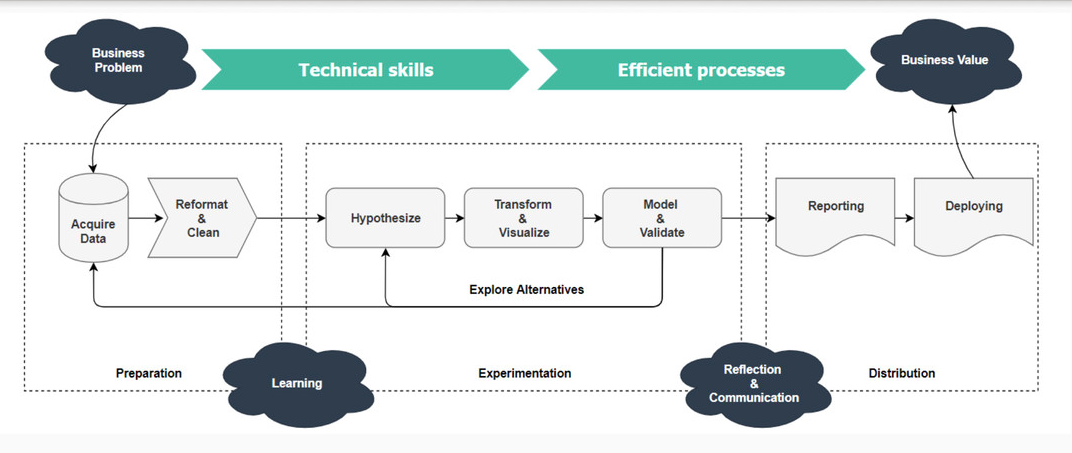
El flujo de trabajo de un proyecto de datos es independiente del aspecto de la continuidad de la ciencia de datos que se está considerando. Los mismos principios se aplican a todo tipo de análisis. En el caso de los proyectos de mayor envergadura, se aconsejan métodos formales de gestión de proyectos para controlar el tiempo, el presupuesto y la calidad.
Conclusion
Como podemos ver, las organizaciones deben hacer un esfuerzo consciente, informado y organizado para convertirse en una empresa basada en datos, lo cual significa que finalmente estarán tomando decisiones sin basarse en caprichos, egos, competencias u otras características, en vez de ello, las decisiones estratégicas e importantes y que generan valor, se toman basados en datos pasados, se analizan en el presente y se trata de predecir un resultado que favorezca la continuidad y las ventajas de la empresa en el mercado.
Por otro lado, vemos que la empresa debe cambiar ciertos procesos internos, y tener un personal adecuado, con el fin de tener una aproximación sofisticada y certera hacia los datos. Si usted desea más información sobre cómo implementar un problema de ciencia de datos podemos ayudarle aquí.
¡Esperamos haya disfrutado de la lectura!






