
Startup, SMB or company founders, managers or decision makers often claim that they are "data rich but information poor". This statement is in many cases only partially correct because it hides a misconception about the data life cycle. The fact that it is data-rich but information-poor suggests that previously untapped data sources are waiting to be exploited and used.
It is very unlikely that any organization will collect data without a particular purpose. In most cases, data is collected to manage operational processes. Collecting data without a particular purpose is a waste of resources. In many companies, once data is used, it is stored and becomes "dark data".
Because almost all operational processes are recorded electronically, data is now everywhere. Managers rightly ask themselves what to do with this information after it has been archived. A strategic approach to data science would help an organization unravel the untapped value of these data stores to better understand their strategic and operational context.
The evolution to become a data-based organization begins with the collection of data generated during operational processes. The next step is to describe this data through exploratory techniques such as visualizations and statistics, which is the domain of traditional business reporting (or what is called today Business Intelligence) that provides insights for decision making.
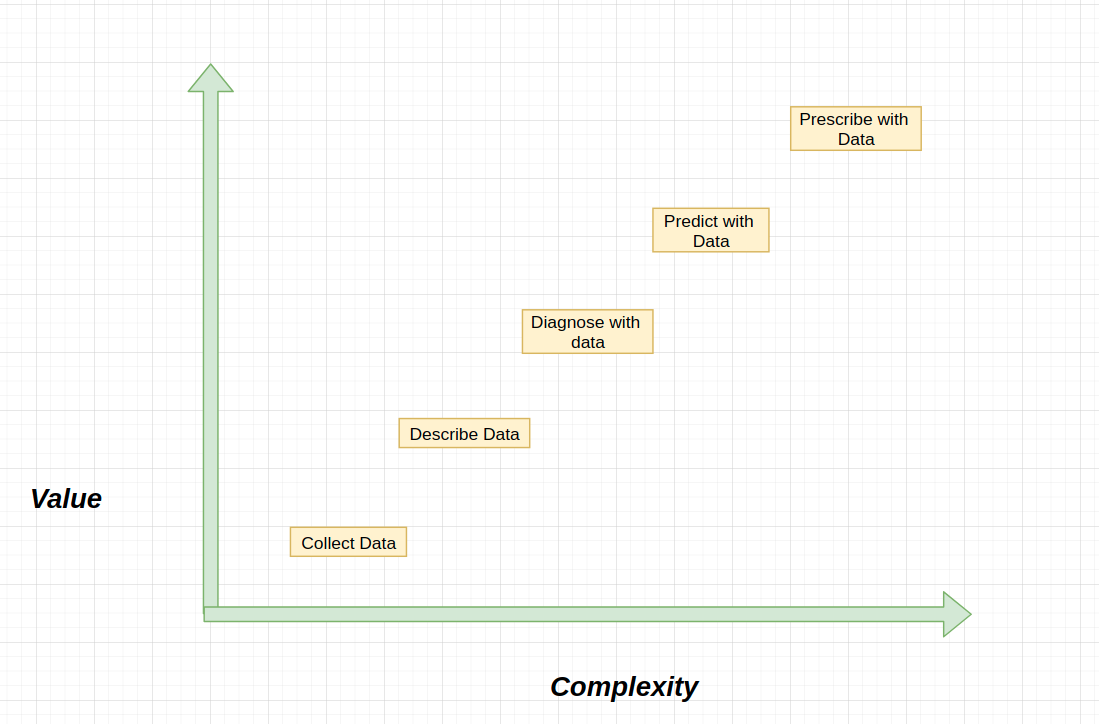
Once the data has been explored and understood, organizations can diagnose business processes to understand the causal and logical relationships between variables. The penultimate phase consists of using knowledge of the past and its causal and logical connections to predict possible futures and build the desired future. The final stage of the data science journey is a situation where data is used to prescribe everyday operations
This process is not a left to right trip, eventually landing in a place where the algorithms control our destiny, and the rest becomes less critical. This process guides the data science strategy to this point, but forms a strict hierarchy.
Before algorithms can decide anything independently, you need to be able to predict the immediate future. To predict the future, you need to have a good understanding of descriptive statistics to diagnose a business process. Finally, the Garbage-In-Garbage-Out (GIGO) principle requires that analysis is only possible if we understand the data collected.
Towards a Data-driven Organization
The process we have just seen provides a strategic map for organizations trying to be more data-driven. Each step in the process is equally important for the next level because these higher levels of complexity cannot be achieved without embracing the lower levels. The most important aspect of the data science process is that it outlines an evolutionary approach to becoming a data-driven organization.
As an organization evolves into more complex forms of data science, the early stages do not become vestigial appendages, but remain an integral part of the data science strategy. All parts of this model have the same relative value.
However, being driven by data is more than a process of increasing complexity. Evidence-based management requires people within the organization to be knowledgeable about data and to work together toward a common goal.
The systematic aspect of data science requires a formalized process to ensure robust results. The increasing complexity of analytical methods also requires investment in better tools and data infrastructure.
There are many technical aspects to consider when applying data science in an organization. However, simply focusing on the technicalities of data analysis is not enough to create value for an organization. A data science manager needs to manage people, systems, and processes to develop a data-based organization.
Decision makers sometimes ignore even the most useful and aesthetic visualizations, even when the analysis is sound. Data science, using best practices, is only the starting point for creating a value-driven organization. A critical aspect of ensuring that managers use results is to foster a data-based culture, which requires managing people.
To allow data science to flourish, the organization needs to have a well-established set of computer systems to store and analyze data and present results. A wide range of data science tools are available, each of which plays a different role in the analysis value chain.
Each data science project begins with a problem definition that is translated into data and code to define a solution. This problem is injected into the data vortex until a solution is found. The data science process discusses the workflow of creating "data products".
The three aspects of becoming a data-based organization and strategically implementing data science require alignment:
As an organization evolves into more complex forms of data science, the early stages do not become vestigial appendages, but remain an integral part of the data science strategy. All parts of this model have the same relative value.
However, being driven by data is more than a process of increasing complexity. Evidence-based management requires people within the organization to be knowledgeable about data and to work together toward a common goal.
The systematic aspect of data science requires a formalized process to ensure robust results. The increasing complexity of analytical methods also requires investment in better tools and data infrastructure.
There are many technical aspects to consider when applying data science in an organization. However, simply focusing on the technicalities of data analysis is not enough to create value for an organization. A data science manager needs to manage people, systems, and processes to develop a data-based organization.
Decision makers sometimes ignore even the most useful and aesthetic visualizations, even when the analysis is sound. Data science, using best practices, is only the starting point for creating a value-driven organization. A critical aspect of ensuring that managers use results is to foster a data-based culture, which requires managing people.
To allow data science to flourish, the organization needs to have a well-established set of computer systems to store and analyze data and present results. A wide range of data science tools are available, each of which plays a different role in the analysis value chain.
Each data science project begins with a problem definition that is translated into data and code to define a solution. This problem is injected into the data vortex until a solution is found. The data science process discusses the workflow of creating "data products".
The three aspects of becoming a data-based organization and strategically implementing data science require alignment:
- People
- Systems and
- Processes
This in order to optimize the value that can be extracted from the available information.
1- People
When talking about the people in a data-based organization, we should not only mention the specialists who create the data products. The members of the data science team possess the competencies shown in the following diagram
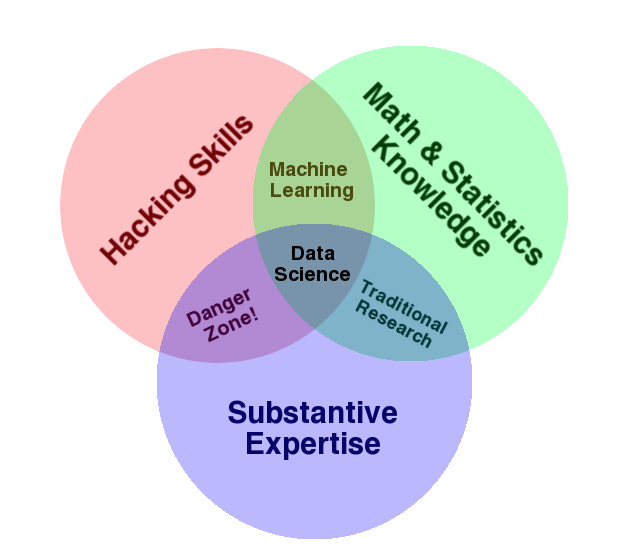
Source here
These clearly technical people must be able to communicate the results of their work to their colleagues or clients and convince them to apply the findings.
Data science does not only occur exclusively within the specialized team. Every data project has an internal or external client who has a problem that needs an answer. The data science team and the users of their products work together to improve the organization.
This implies that a data scientist needs to understand the basic principles of organizational behavior and change management and be a good communicator. In contrast, recipients of data science need to have sufficient knowledge of the data to understand how to interpret and use the results.
2- Systems
Like any other profession, a data scientist needs an appropriate set of tools to create value from the data. There are a number of data science solutions available on the market, many of which are open source software. There are specialized tools for every aspect of the data science workflow.
There is no need to discuss the multitude of packages that are available. Many excellent websites examine the various offerings. We will instead offer some thoughts on the use of Excel (or any other spreadsheet) versus code writing and business intelligence platforms.
Spreadsheets are a versatile tool for analyzing data that has proliferated in almost every aspect of business. However, this universal tool is not very suitable for undertaking complex and sophisticated data science. One of the perceived advantages of spreadsheets is that they contain the data, code and output in one convenient file. This convenience comes at a price, as it reduces the robustness of the analysis.
Anyone who has ever had the displeasure of reverse engineering a spreadsheet will understand the limitations of spreadsheets. In spreadsheets, it is not immediately clear which cell is the result of another cell and what the original data is.
Many organizations use spreadsheets as the only source of truth for business data, which should be avoided if information needs to be shared. The best practice of data science is to separate the data, the code and the result.
As mentioned above, the best way to create unicorns in data science is to teach experts in the field how to write analytical code. Writing code with R or Python is like writing an instruction manual on how to analyze data. Anyone who understands the language will be able to know how their conclusions are derived.
Modern data science languages can generate print-quality visualizations and can produce results in many formats, including a spreadsheet or standalone application.
The gold standard for programming in data science is well-documented programming. This technique combines code with "pseudocode" (or to make it easier, it is to make comments next to the written code, and thus explain how it was created and what its function is) and thus allow the algorithm to be fully understood. All programming languages include the ability to add these comments.
Each language has its own methods for combining text with code. RMarkdown, Jupyter Notebooks and Org Mode are popular systems for data analysis and allow easy understanding of these comments (even as a blog post with text editing). Once the code is written, at the touch of a button the machine generates a new report with updated statistics and graphics.
Finally, Business Intelligence tools are useful for disseminating the results of a data science project, but are not very useful for detailed analysis. A platform like Power BI is a great system to visualize the result of an analysis because it provides very flexible ways to cut and slice the data and visualize the results. The analytical capabilities of the platform are not very high but can be modified by inserting code in Python or R to complement its capabilities.
Also read: Why are data science competitions important for startups?
3- Processes
The process of creating value from data follows an iterative workflow that works from raw data to a finished project.
The workflow starts with the definition of a problem that needs to be solved as shown in the figure below. The next step involves loading and transforming the data into a format suitable for the required analysis. The data science workflow contains a loop consisting of exploration, modeling, and reflection, which is repeated until the problem is solved or shown to be unsolvable.
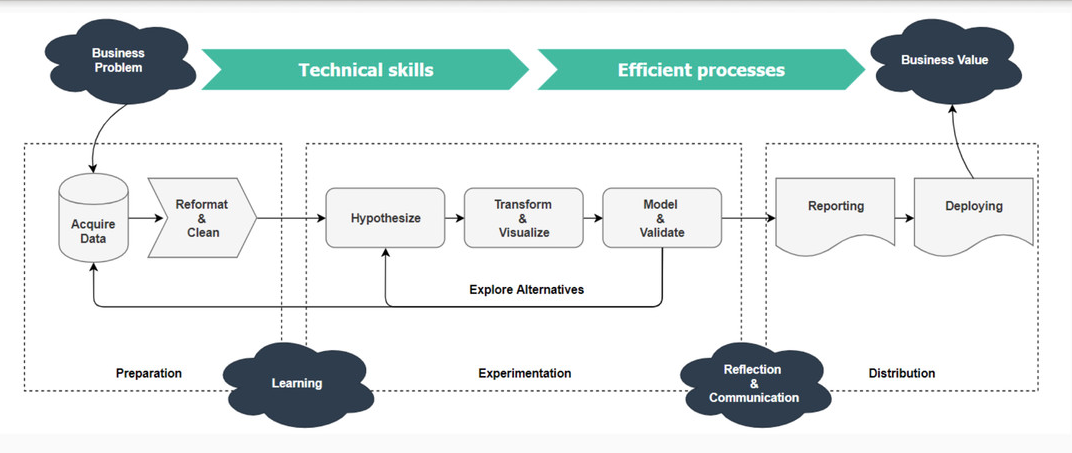
Source
The workflow of a data project is independent of the data science continuity aspect being considered. The same principles apply to all types of analysis. For larger projects, formal project management methods are advised to control time, budget, and quality.
Conclusion
As we can see, organizations must make a conscious, informed and organized effort to become a data-based company, which means that they will finally be making decisions without relying on whims, egos, competencies or other characteristics. Instead, strategic and important decisions that generate value are made based on past data, analyzed in the present and it is a matter of predicting a result that favors the continuity and advantages of the company in the market.
On the other hand, we see that the company must change certain internal processes, and have adequate personnel, in order to have a sophisticated and accurate approach to data. If you want more information about how to implement a data science problem we can help you here.
We hope you enjoyed reading!








