
There are so many websites out there offering job listings for different fields of jobs. Even though you might be at a certain position you should
always look for a job and that can get boring. But here comes a simple solution in order to get through so many of those job offers with ease!
We are going to build an easy Python script to get job listings and filter them to your likings.
It is a simple use of Python and you do not need any specific skills to do this with me. We will go step by step and build everything together.
Let’s just jump right into it!

Coding
Plan the process
First, we have to find the job listing website that we are going to get the offers from.
I choose a website called Indeed. (It is just an example for this tutorial, but If you have a website you prefer to use for job hunting, please feel free to do so!)
Here is what we are going to do:
Filter the criteria of jobs that fit us and perform scraping on those.
Here is what Indeed’s website looks like after I search for Data Science in United States.

In the end, once we have our data, we are going to pack it into DataFrames and get a CSV file, which can be opened easily with Excel or Libre Office.

Setting up the environment
You are going to have to install a ChromeDriver and use it with Selenium, which is going to enable us to manipulate the browser and send commands to it for testing and after for use.
Open the link and download the file for your operating system. I recommend the latest stable release unless you know what you are doing already.
Next up, you need to unzip that file. I would recommend going into Files and doing it manually by right-clicking and then “Extract here”.

Inside the folder, there is a file called “chromedriver”, which we have to move to a specific folder on your computer.
Open the terminal and type these commands:
sudo su #enter the root mode cd #go back to base from the current location mv /home/*your_pc_name*/Downloads/chromedriver /usr/local/bin #move the file to the right location
Just instead of *your_pc_name* insert your actual name of the computer.
There are a few more libraries needed for this to work:
In that terminal you should install these:
pip3 install pandas
Pandas is a fast, powerful, flexible, and easy to use open-source data analysis and manipulation tool, built on top of the Python programming language.
sudo pip3 install beautifulsoup4
Beautiful Soup is a Python library for getting data out of HTML, XML, and other markup languages.
Once we are done with that, we open the editor. My personal choice is Visual Studio Code. It is straightforward to use, customizable, and light for your computer.
Open a new Project where ever you like and create two new files. This is an example of how mine looks like to help you:
In the VS Code, there is a “Terminal” tab with which you can open an internal terminal inside the VS Code, which is very useful to have everything in one place.
When you have that open, there is few more thing we need to install and that is the virtual environment and selenium for web driver. Type these commands into your terminal.
pip3 install virtualenv source venv/bin/activate pip3 install selenium
After activating the virtual environment, we are completely ready to go.

Creating the Tool
We have everything set up and now we are going to code!
First, as mentioned before, we have to import installed libraries.
from selenium import webdriver import pandas as pd from bs4 import BeautifulSoup from time import sleep
Create your tool with any name and start the driver for Chrome.
class FindJob():
def __init__(self):
self.driver = webdriver.Chrome()That is all we need to start developing. Now go to your terminal and type:
python -i findJob.py
This command lets us our file as an interactive playground. The new tab of the browser will be opened and we can start issuing commands to it.
If you want to experiment you can use the command line instead of just typing it directly to your source file. Just instead of self use bot.
For Terminal:
bot = FindJob()
bot.driver.get('https://www.indeed.com/jobs?q=data+science&l=United+States&start=')And now for the source code:
self.driver.get('https://www.indeed.com/jobs?q=data+science&l=United+States&start=')Creating the DataFrame we are going to be using is easy, so let’s begin there!
For this data frame, we need to have “Title”, “Location”, “Company”, “Salary”, “Description” all related to the jobs we are going to scrape.
dataframe = pd.DataFrame( columns=["Title", "Location", "Company", "Salary", "Description"])
We will use this DataFrame as a Column names for our CSV file.
The thing with this website is that on every page there are 10 job offers and the link changes as you go to the next page. Once I have figured that out, I made a for loop that checks every page and after it is done it goes to the next one. Here is what that looks like:
for cnt in range(0, 50, 10):
self.driver.get("https://www.indeed.com/jobs?q=data+science&l=United+States&start=" + str(cnt))I set up a counter variable ‘cnt’ and add that number, converted to string to my link. The for loop specifically begins with 0 goes up to 50 and does it in iterations of 10 because that is how many jobs per page Indeed shows us.
When we get to the first page, we need to scrape the table of offers one by one and we are going to do it this way:
In the image above, where you see offers, they are packed in a table and we can find that table by pressing F12 on keyboard or right-click -> Inspect.
Here is what that looks like:
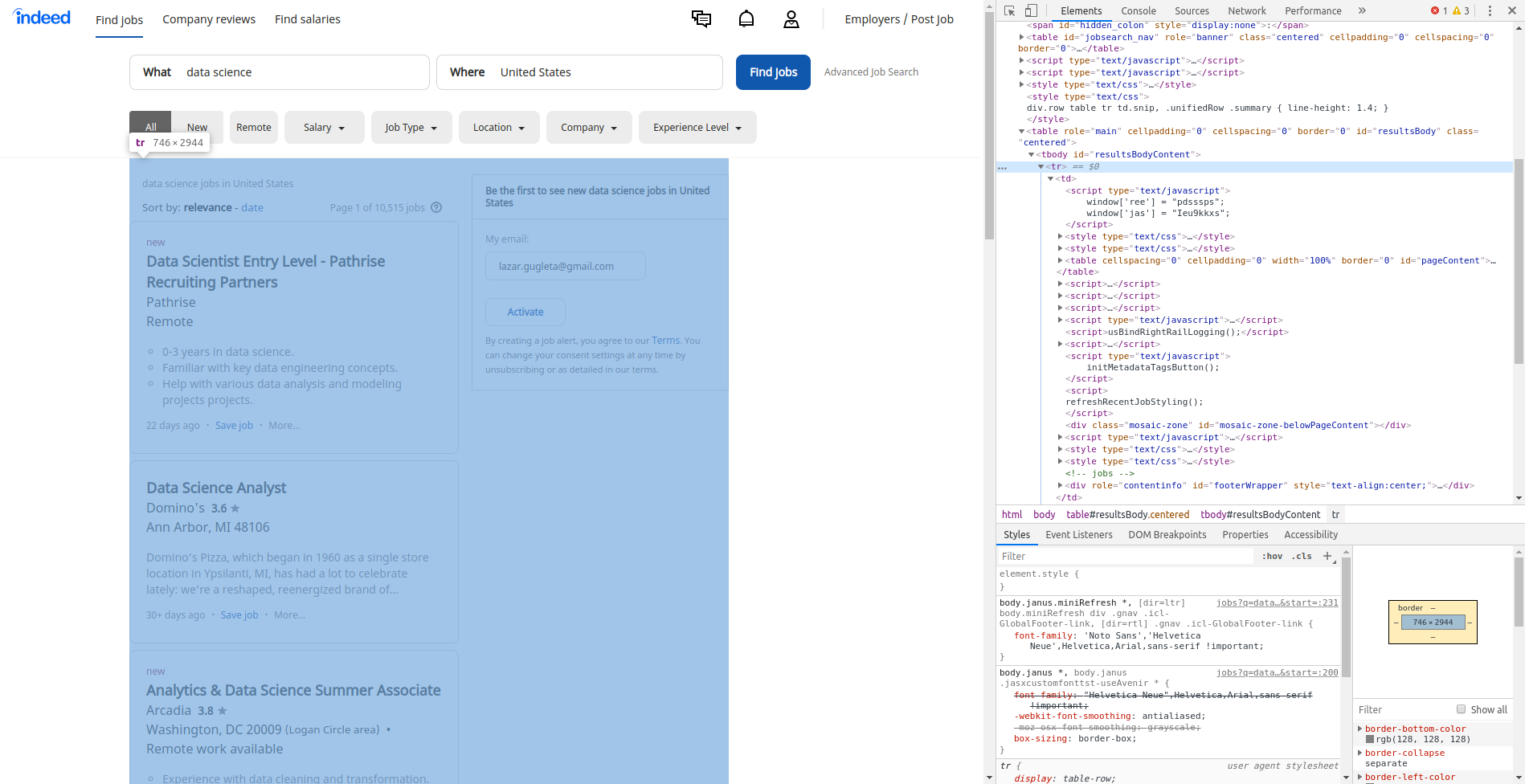
We will find the table by the class name and we enter this line:
jobs = self.driver.find_elements_by_class_name('result')That saves all Web elements that it has found by the class name result.
Once we have those saved we can create another for loop and go through every element inside that table and use that data we found inside.
Before I show you more code on scraping those offers, we should go through a couple of things.
For this part, we are going to use BeautifulSoup since I find it to work way faster.
We have to set up a few things for BeatifulSoup, and those are the actual data that we give it to perform its search on and parser that we say it should use:
result = job.get_attribute('innerHTML')
soup = BeautifulSoup(result, 'html.parser')Once we get those, we just have to find elements inside the ‘soup’ defined variable, which is just a prepared data by BeautifulSoup.
We get the data for the DataFrame that we want:
title = soup.find("a", class_="jobtitle").text.replace('\n', '')
location = soup.find(class_="location").text
employer = soup.find(class_="company").text.replace('\n', '').strip()
try:
salary = soup.find(class_="salary").text.replace(
'\n', '').strip()
except:
salary = 'None'I did a salary part in such a manner because sometimes it is not defined and we have to set None or empty for that particular cell.
Since I am working in the terminal for testing my code, you can also print what you found so far:
print(title, location, employer, salary)
Once this script is done, it will look like this:

The last thing missing for the DataFrame is the Description of the job and left this out because, in order to get the text for the job description, you have to click the job offer first. I do it this way:
summ = job.find_elements_by_class_name("summary")[0]
summ.click()
job_desc = self.driver.find_element_by_id('vjs-desc').textAfter we got all elements that should go into the DataFrame, we fill it:
dataframe = dataframe.append(
{'Title': title, 'Location': location, 'Employer': employer, 'Description': job_desc}, ignore_index=True)
One more thing that I have to mention before you start testing this for yourself.
Once you go to the second page of the website, there is a popup that blocks you from clicking further on anything!
I also thought of that and created a try-expect, which will close the popup and continue scraping data!
pop_up = self.driver.find_element_by_xpath('/html/body/table[2]/tbody/tr/td/div[2]/div[2]/div[4]/div[3]/div[2]/a')
pop_up.click()
Once the for loop finishes, we copy the data frame data to CSV called ‘jobs’:
dataframe.to_csv("jobs.csv", index=False)We are done!
Next steps
You can take this script to another level by implementing a comparison between different websites and get the best offers on the internet overall.
You can find a job in Python here.
Until then, follow me for more! 😎
Thanks for reading!








