
I'm often asked, "what kind of machine learning project should I work on?"
And I usually answer with "follow your curiosity."
Why?
Because of how experimental machine learning is, it's in your best interest to figure things out through tinkering. By trying things which might not work.
However, machine learning projects are no longer works of magic. The device you're reading this on probably uses machine learning in several different ways you're not aware of (see Apple's implicit machine learning below).
That being said, this issue of ML Monthly (April 2021 edition) collects different design best practices from companies using machine learning at world-scale proportions.
And after reading through them, you'll start to notice there are many overlaps in how things are done. This is a good thing. Because the overlaps are what you can use for your own projects.
As models and machine learning code become more and more reproducible, you'll notice an overarching theme here: machine learning is an infrastructure problem.
Which is something you've known all along, "how do I get data from one place to another in the fastest, most efficient way possible?"
If you're considering working on your own machine learning projects, read through each of the guidelines below and try the materials in the bonuses section, but remember, none of these will replace the knowledge you gain from experimenting yourself (guidelines, schmuidelines).
Note: I have used the terms machine learning and artificial intelligence (AI) interchangeably throughout this article. You can read "machine learning system" as "AI system" and vice versa.
Apple’s Human Interface Guidelines for Machine Learning
I'm writing these lines on an Apple MacBook in a library where I can see at least 6 other Apple logos. This morning I watched two people in front of me pay for their coffee using their iPhones.
Apple devices are everywhere.
And they all use machine learning in many different ways, to enhance photos, to preserve battery life, to enable voice searches with Siri, to suggest words for quick type.
Apple's Human Interface Guidelines for Machine Learning share how they think about and how they encourage developers to think about using machine learning in their applications.
They start with two high-level questions and break it down from there:
- What is the role of machine learning in your app?
- What are the inputs and outputs?
For the role of machine learning in your app, they go on to ask, is it critical (need to have) or complementary (nice to have)? Is it private or public? Is it visible or invisible? Dynamic or static?
For the inputs and outputs (I'm a big fan of this analogy because it's similar to a ML model's inputs and outputs) they discuss what a person will put into your system and what your system will show them.
Does a person give a model explicit feedback? As in, do they tell your model if it's right or wrong? Or does your system gather implicit feedback (feedback which doesn't require a person to do any extra work other than use the app)?
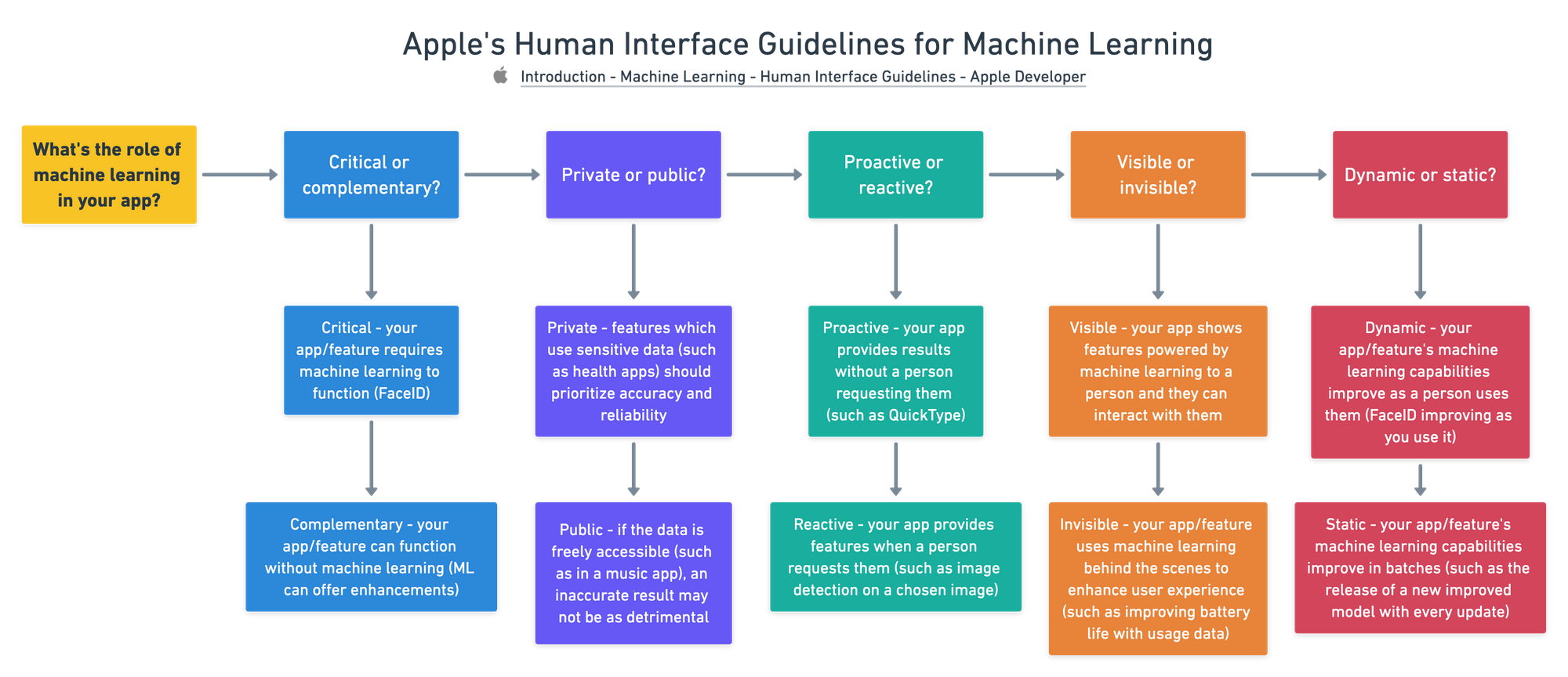
Questions to think about when asking what role machine learning plays in your app/feature. Source:https://developer.apple.com/design/human-interface-guidelines/machine-learning/overview/roles/
Google's People and AI Research (PAIR)
Google's design principles for AI can be found in their People and AI Research (PAIR) guidebook.
The PAIR guidebook also comes along with a great glossary of many different machine learning terms you'll come across in the field (there's a lot). It breaks down designing an AI project into six sections.
User Needs + Defining Success
- Where's the intersection of what AI is capable of and what the people using your service require?
- Should you automate (remove a painful task) or augment (improve) with AI?
- What's the ideal outcome?
Data Collection + Evaluation
- Turn a person's requirements into data requirements (it all starts with the data)
- Where does your data come from? (is it responsibly sourced?)
- Build, fit and tune your model (good models start with good data)
Mental Models (setting expectations)
- What does a person believe your ML system can achieve?
Explainability + Trust
- AI systems are probability-based (and may give strange results), how can this be explained?
- What information should a person know about how a ML model made a decision? (confidence levels, "we're showing you this because you liked that...")
Feedback + Control
- How can a person give feedback to help your system improve?
Errors + Graceful Failure
- What is an "error" and what is a "failure"? (a self-driving car stopping at a green light could be an error but running a red light could be a failure)
- ML systems aren't perfect and your system will eventually fail, what do you do when it does?
Each section comes with a worksheet to practice what you've learned.
A trend you'll notice after going through the guidelines (especially PAIR) is setting expectations. Being upfront with what your system is capable of. If a person expects your system to be magic (as ML is often portrayed) but isn't aware of its limitations, they may be let down.
Also read: Customize your Jupyter Notebooks
Microsoft's design guidelines for Human-AI interaction
Microsoft's design guidelines for Human-AI interaction tackle the problem in four stages:
- Initially (what should a person know when they first use your system?)
- During interaction (what should happen whilst a person is using your service?)
- When wrong (what happens when your system is wrong?)
- Over time (how does your system improve over time?)
You'll notice Microsoft's guidelines take you on a walk in a person using your ML system's shoes. And again we see a trend.
Problem → Create solution (ML or not) → Set expectations → Allow feedback → Have a mechanism for when it's wrong → Improve over time (go back to the start).

Microsoft's guidelines for Human-AI interaction cards, starting with initial stages through to what to do as a person interacts with your machine learning system over time. Source: https://www.microsoft.com/en-us/research/project/guidelines-for-human-ai-interaction/
Facebook’s Field Guide to Machine Learning
While previous resources have taken the approach of an overall ML system, Facebook's Field Guide to Machine Learning focuses more on the modelling side of things.
Their video series breaks a machine learning modelling project into six parts:
- Problem definition — what problem are you trying to solve?
- Data — what data do you have?
- Evaluation — what defines success?
- Features — what features of the data best align with your measure of success?
- Model — what model best suits the problem and data you have?
- Experimentation — how can you iterate and improve upon the previous steps?
But as the modelling side of things in machine learning gets more accessible (thanks to pretrained models, existing codebases, etc), it's important to keep in mind all of the other parts of machine learning.
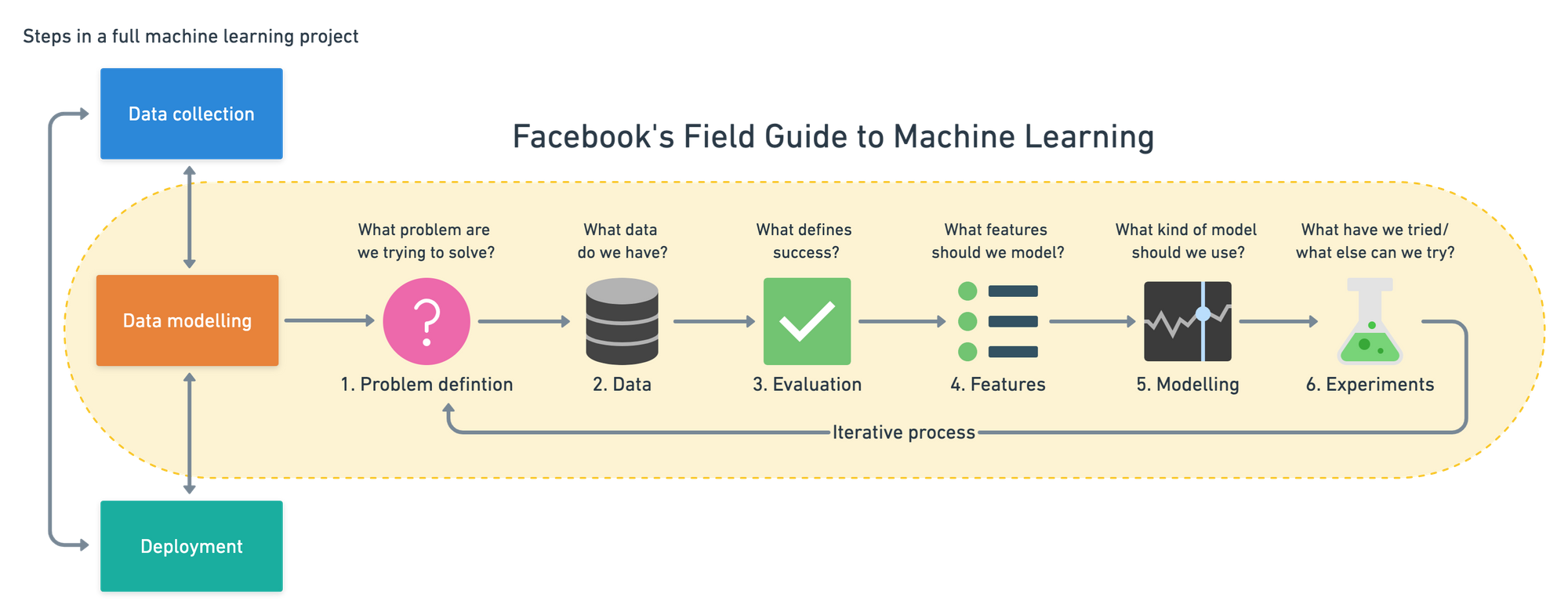
I used Facebook's Field Guide to Machine Learning as the outline of the Zero to Mastery Data Science and Machine Learning Course. You can also read an expanded version of these steps on my blog.
Spotify’s 3 Principles for Designing ML-Powered Products
How do you build a service which provides music to 250 million users across the world?
You start by going manual before you go magic (principle 3) and you continually ask the right questions (principle 2) to identify where the people using your service are facing friction (principle 1).
The sentence above is a play on words of Spotify's three principles for designing machine learning-powered products.
Principle 1: Identify friction and automate it away
Anywhere a person struggles in pursuit of their goals whilst using your service can be considered friction.
Imagine a person searching for new music on Spotify but unable to find anything which suits their tastes. Doing so could hurt someone's experience.
Spotify realized this and used machine learning-based recommendation systems to create Discover Weekly (what I'm currently listening to), a playlist which refreshes with new music every week.
And in my case, it looks like they must've adhered to their other two principles whilst building it because these tracks I'm listening to are bangers.
Principle 2: Ask the right questions
Ask. Ask. Ask. If you don't know, you could end up designing a product in the wrong direction.
Much like many of the other guideline steps above challenge you to think from the person using your service's point of view, this is the goal of asking the right questions: find out what issues your customers are having and see if you can solve them using machine learning.
Principle 3: Go manual before you go magical
Found a source of friction?
Can you solve it without machine learning?
How about starting with a heuristic (an idea of how things should work)?
Like if you were Spotify and trying to build a playlist of new music someone was interested in, how do you classify something as new?
Your starting heuristic could be anything older than 30 days wouldn't be classified as new.
After testing multiple heuristics and hypotheses (a manual process) you could then again review whether or not machine learning could help. And because of your experiments, you'd be doing so from a very well-informed point of view.
Also read: Building a Product Recommendation System with Collaborative Filtering
From Big Data to Good Data by Andrew Ng
Andrew Ng presented a talk at Scale's recent conference on the movement of ML systems from big data to good data. And Roboflow did a great summary of the main points — all of which talk to the things we've discussed above.
Some of my favourites include:
- Getting to deployment is a starting point rather than the finish line (closing the proof of concept and production gap)
- From big data to good data (MLOps' most important task is ensuring high-quality data in all phases of the ML project lifecycle and not all companies have access to big data)
- Freeze your codebase and iterate on your data (for many problems the model is a solved problem, the data is what's needed)

Andrew Ng on the importance of thinking about good data as well as big data. Source: https://scale.com/events/transform/videos/big-data-to-good-data
Learning more
The above are all guidelines on how to think about building ML-powered systems. But they don't show you tools or how to go about doing so.
The following are extra resources I'd recommend for filling the gaps left by the above.
Choose one and read through/work through all the materials/labs whilst building your own ML-powered project.
- Engineering best practices for machine learning (Software Engineering 4 Machine Learning) — a thorough guide on developing software systems with machine learning components.
- Machine Learning Engineering Book by Andriy Burkov — a one stop shop for many of the guidelines and steps discussed above, I have this book on my desk and use it as a reference.
- CS329s: Machine Learning System Design — an entire Stanford course covering all of the steps that go into a designing a machine learning-powered system. Led by Chip Huyen with guest lectures (including one from yours truly) by engineers from many different machine learning companies.
- Full Stack Deep Learning — machine learning doesn't stop once a model is built (and after reading the above, you know the model is a small part of the entire system). Full Stack Deep Learning introduces many of the steps around model building such as data storage, data manipulation, data versioning (notice the emphasis on data), model deployment as well as different tools for implementing them.
- Made with ML MLOps curriculum — MLOps = machine learning operations. Made with ML MLOps is made by Goku Mohandas in apprenticeship style, "here's how I would build an ML-powered service and how you can too".
- LJ Miranda's outstanding blog post on software engineering skills for data scientists– if I was to write a blog post specifically on going from building models (in notebooks) to writing full-stack code, this would be it.
[This post originally appeared as the April 2021 issue of Machine Learning Monthly, a monthly newsletter I write containing the latest and greatest (but not always latest) of the machine learning field.]









