
The popularity of data science attracts a lot of people from a wide range of professions to make a career change with the goal of becoming a data scientist.
Despite the high demand for data scientists, it is a highly challenging task to find your first job. Unless you have a solid prior job experience, interviews are where you can show you skills and impress your potential employer.
Data science is an interdisciplinary field which covers a broad range of topics and concepts. Thus, the number of questions that you might be asked at an interview is very high.
However, there are some questions about the fundamentals in data science and machine learning. These are the ones you do not want to miss. In this article, we will go over 10 questions that are likely to be asked at a data scientist interview.
The questions are grouped into 3 main categories which are machine learning, Python, and SQL. I will try to provide a brief answer for each question. However, I suggest reading or studying each one in more detail afterwards.
Machine Learning
1. What is overfitting?
Overfitting in machine learning occurs when your model is not generalized well. The model is too focused on the training set. It captures a lot of detail or even noise in the training set. Thus, it fails to capture the general trend or the relationships in the data. If a model is too complex compared to the data, it will probably be overfitting.
A strong indicator of overfitting is the high difference between the accuracy of training and test sets. Overfit models usually have very high accuracy on the training set but the test accuracy is usually unpredictable and much lower than the training accuracy.
2. How can you reduce overfitting?
We can reduce overfitting by making the model more generalized which means it should be more focused on the general trend rather than specific details.
If it is possible, collecting more data is an efficient way to reduce overfitting. You will be giving more juice to the model so it will have more material to learn from. Data is always valuable especially for machine learning models.
Another method to reduce overfitting is to reduce the complexity of the model. If a model is too complex for a given task, it will likely result in overfitting. In such cases, we should look for simpler models.
3. What is regularization?
We have mentioned that the main reason for overfitting is a model being more complex than necessary. Regularization is a method for reducing the model complexity.
It does so by penalizing higher terms in the model. With the addition of a regularization term, the model tries to minimize both loss and complexity.
Two main types of regularization are L1 and L2 regularization. L1 regularization subtracts a small amount from the weights of uninformative features at each iteration. Thus, it causes these weights to eventually become zero.
On the other hand, L2 regularization removes a small percentage from the weights at each iteration. These weights will get closer to zero but never actually become 0.
4. What is the difference between classification and clustering?
Both are machine learning tasks. Classification is a supervised learning task so we have labelled observations (i.e. data points). We train a model with labelled data and expect it to predict the labels of new data.
For instance, spam email detection is a classification task. We provide a model with several emails marked as spam or not spam. After the model is trained with those emails, it will evaluate the new emails appropriately.
Clustering is an unsupervised learning task so the observations do not have any labels. The model is expected to evaluate the observations and group them into clusters. Similar observations are placed into the same cluster.
In the optimal case, the observations in the same cluster are as close to each other as possible and the different clusters are as far apart as possible. An example of a clustering task would be grouping customers based on their shopping behavior.
Python
The built-in data structures are of crucial importance. Thus, you should be familiar with what they are and how to interact with them. List, dictionary, set, and tuple are 4 main built-in data structures in Python.
5. What is the difference between lists and tuples
The main difference between lists and tuples is mutability. Lists are mutable so we can manipulate them by adding or removing items.
mylist = [1,2,3] mylist.append(4) mylist.remove(1) print(mylist) [2,3,4]
On the other hand, tuples are immutable. Although we can access each element in a tuple, we cannot modify its content.
mytuple = (1,2,3) mytuple.append(4) AttributeError: 'tuple' object has no attribute 'append'
One important point to mention here is that although tuples are immutable, they can contain mutable elements such as lists or sets.
mytuple = (1,2,["a","b","c"]) mytuple[2] ['a', 'b', 'c'] mytuple[2][0] = ["A"] print(mytuple) (1, 2, [['A'], 'b', 'c'])
6. What is the difference between lists and sets
Let’s do an example to demonstrate the main difference between lists and sets.
text = "Python is awesome!"
mylist = list(text)
myset = set(text)
print(mylist)
['P', 'y', 't', 'h', 'o', 'n', ' ', 'i', 's', ' ', 'a', 'w', 'e', 's', 'o', 'm', 'e', '!']
print(myset)
{'t', ' ', 'i', 'e', 'm', 'P', '!', 'y', 'o', 'h', 'n', 'a', 's', 'w'}As we notice in the resulting objects, the list contains all the characters in the string whereas the set only contains unique values.
Another difference is that the characters in the list are ordered based on their location in the string. However, there is no order associated with the characters in the set.
Here is a table that summarizes the main characteristics of lists, tuples, and sets.
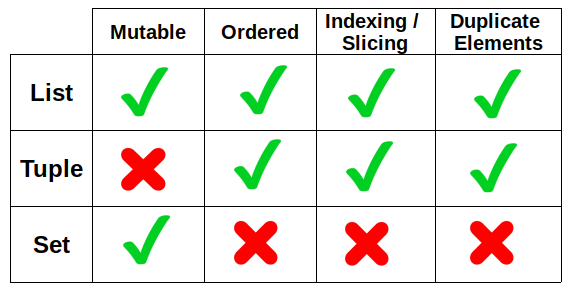
(image by author)
7. What is a dictionary and what are the important features of dictionaries?
A dictionary in Python is a collection of key-value pairs. It is similar to a list in the sense that each item in a list has an associated index starting from 0.
mylist = ["a", "b", "c"] mylist[1] "b"
In a dictionary, we have keys as the index. Thus, we can access a value by using its key.
mydict = {"John": 24, "Jane": 26, "Ashley": 22}
mydict["Jane"]
26The keys in a dictionary are unique which makes sense because they act like an address for the values.
SQL
SQL is an extremely important skill for data scientists. There are quite a number of companies that store their data in a relational database. SQL is what is needed to interact with relational databases.
You will probably be asked a question that involves writing a query to perform a specific task. You might also be asked a question about general database knowledge.
8. Query example 1
Consider we have a sales table that contains daily sales quantities of products.
SELECT TOP 10 * FROM SalesTable
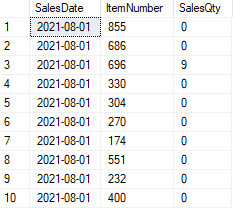
(image by author)
Find the top 5 weeks in terms of total weekly sales quantities.
SELECT TOP 5 CONCAT(YEAR(SalesDate), DATEPART(WEEK, SalesDate)) AS YearWeek, SUM(SalesQty) AS TotalWeeklySales FROM SalesTable GROUP BY CONCAT(YEAR(SalesDate), DATEPART(WEEK, SalesDate)) ORDER BY TotalWeeklySales DESC
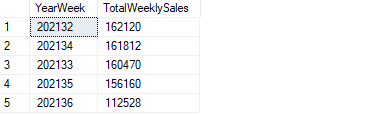
(image by author)
We first extract the year and week information from the date column and then use it in the aggregation. The sum function is used to calculate the total sales quantities.
9. Query example 2
In the same sales table, find the number of unique items that are sold each month.
SELECT MONTH(SalesDate) AS Month, COUNT(DISTINCT(ItemNumber)) AS ItemCount FROM SalesTable GROUP BY MONTH(SalesDate) Month ItemCount 1 9 1021 2 8 1021
10. What is normalization and denormalization in a database?
These terms are related to database schema design. Normalization and denormalization aim to optimize different metrics.
The goal of normalization is to reduce data redundancy and inconsistency by increasing the number of tables. On the other hand, denormalization aims to speed up the query execution. Denormalization decreases the number of tables but at the same time, it adds some redundancy.
Conclusion
It is a challenging task to become a data scientist. It requires time, effort, and dedication. Without having prior job experience, the process gets harder.
Interviews are very important to demonstrate your skills. In this article, we have covered 10 questions that you are likely to encounter in a data scientist interview.
Thank you for reading. Please let me know if you have any feedback.









