

An overview of Machine Learning Algorithms(Source)
“Machine intelligence is the last invention that humanity will ever need to make.”
— Nick Bostrom.
If you could look back a couple of years ago at the state of AI and compare it with its current state, you would be shocked to find how exponentially it has grown over time.
It has branched out into a variety of domains such as ML, Expert Systems, NLP, and dozens more.
While the idea behind AI is to build smarter systems that think and execute on their own, they still need to be trained.
The ML domain of AI has been created for the very exact purpose by bringing several algorithms, allowing for smoother data processing and decision-making.
What is Machine Learning Algorithms?
ML algorithms are the brains behind any model, allowing machines to learn, making them smarter.
The way these algorithms work is, they’re provided with an initial batch of data, and with time, as algorithms develop their accuracy, additional data is introduced into the mix.
This process of regularly exposing the algorithm to new data and experience improves the overall efficiency of the machine.
ML algorithms are vital for a variety of tasks related to classification, predictive modeling, and analysis of data.
“A breakthrough in machine learning would be worth ten Microsofts.”
- Bill Gates
Types of Machine Learning Algorithms
In this section, we will focus on the various types of ML algorithms that exist. The three primary paradigms of ML algorithms are:
● Supervised Learning
As the name suggests, Supervised algorithms work by defining a set of input data and the expected results. By iteratively executing the function on the training data and involving the user for introducing control parameters, the model is improved. The algorithm is considered a success when its mappings and predictions are found to be correct.
Supervised Learning(source)
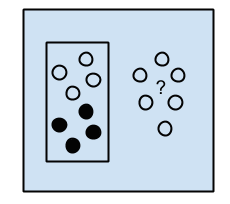
● Unsupervised Learning
While Supervised algorithms work on user-labeled data for output predictions, these train machines explicitly on unlabelled data with little to no user involvement.
Algorithms are left with the data to classify and group them to identify some hidden or undiscovered pattern and is often used as a preliminary step for supervised learning.
Unsupervised Learning(source)
● Reinforcement Learning
Reinforcement learning algorithms aim to find a perfect balance between exploration and exploitation without requiring labeled data or user intervention.
These algorithms work by choosing an action and observing the consequences, based on that, it learns how optimal the result is. This process is repeated time and again until the algorithm evolves and chooses the right strategy.
Top Machine Learning Algorithms
After familiarizing yourself with the several types of ML algorithms, read on for some of the popular ones.
1. Linear Regression
Linear Regression is a supervised ML algorithm that helps find a suitable approximate linear fit to a collection of points.
At its core, linear regression is a linear approach to identifying the relationship between two variables with one of these values being a dependent value and the other being independent.
The idea behind this is to understand how a change in one variable impacts the other, resulting in a relationship that can be positive or negative.
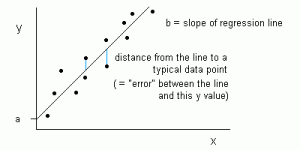

Linear Regression is represented as a line in the form of y = a + bx(source)
This line is known as the regression line and represented by a linear equation Y= a *X + b.
In this equation:
- Y — Dependent Variable
- a — Slope
- X — Independent variable
- b — Intercept
This algorithm applied in cases where the predicted output is continuous and has a constant slope, such as:
- Estimating sales
- Assessing risk
- Weather data analysis
- Predictive Analytics
- Customer survey results analysis
- Optimizing product prices
Useful links:
2. Logistic Regression
Logistic Regression algorithm is often used in the binary classification problems where the events in these cases commonly result in either of the two values, pass or fail, true or false.
It is best suited for situations where there is a need to predict probabilities that the dependent variable will fall into one of the two categories of the response.
Common use cases for this algorithm would be to identify whether the given handwriting matches to the person in question, will the prices of oil go up in coming months.

Logistic Regression algorithm(source)
In general, regressions can be used in real-world applications such as:
- Credit Scoring
- Cancer Detection
- Geographic Image Processing
- Handwriting recognition
- Image Segmentation and Categorization
- Measuring the success rates of marketing campaigns
- Predicting the revenues of a certain product
- Is there going to be an earthquake on a particular day?
Useful links:
3. Decision Trees
Decision Tree algorithm comes under supervised ML and is used for solving regression and classification problems. The purpose is to use a decision tree to go from observations to processing outcomes at each level.
Processing decision trees is a top-down approach where the best suitable attribute from the training data is selected as the root and, the process is repeated for each branch. Decision Trees are commonly used for:
- Building knowledge management platforms
- Selecting a flight to travel
- Predicting high occupancy dates for hotels
- Suggest a customer what car to buy
- Forecasting predictions and identifying possibilities in various domains
Decision Tree algorithm(source)
Useful links:
- sklearn.ensemble.RandomForestClassifier
- sklearn.ensemble.GradientBoostingClassifier
- XGBoost Documentation
- https://catboost.yandex/
- Understanding Random Forests: From Theory to Practice
- Practical XGBoost in Python
4. Apriori Machine Learning Algorithm
It is the algorithm behind the popular recommendation system called “You may also like” on several online platforms.
It operates by searching for common sets of items in the datasets and later builds associations on them.
It is generally used for itemset mining and association rule learning from relational databases.
The idea behind this algorithm is to keep extending related items to a larger set as possible to create a more useful association.
Applications for this algorithm include highlighting buying trends in the market.
Moreover, it is easier to implement and can be used with large datasets.
5. Naive Bayes
Naive Bayes classifiers are categorized as a highly effective supervised ML algorithm and are one of the simplestBayesian Network models.
It works by applying the Bayes’ theorem on data with a naive assumption of conditional independence between every pair of features, given the value of the class variable.

Naive Bayes(source)
In simpler terms, it helps find the probability of an event A happening, given that event B has occurred. Naive Bayes is best for —
- Filtering spam messages
- Recommendation systems such as Netflix
- Classify a news article about technology, politics, or sports
- Sentiment analysis on social media
- Facial recognition software
6. Artificial Neural Networks
Modeled after the human brain, the Artificial Neural Network acts as an enormous labyrinth of neurons or simply, nodes moving information to and from each other.
These interconnected nodes pass data instantaneously to other nodes via the edges for swift processing, facilitating smoother learning.
ANNs learn with examples, instead of being programmed with a specific set of rules. Able to model nonlinear processes, they can be implemented in areas such as —
- Pattern recognition
- Cybersecurity
- Data mining
- Detecting varieties of cancer in patients

Artificial Neural Networks(source)
7. K-means Clustering
k-means clustering is an iterative unsupervised learning algorithm that partitions n observations into k clusters where each observation belongs to the nearest cluster mean.
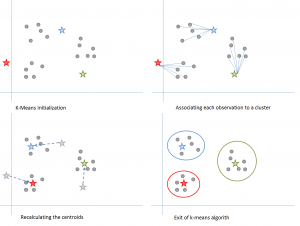
Steps of the K-means algorithm(source)
In simpler terms, this algorithm aggregates a collection of data points based on their similarity. Its applications range from clustering similar and relevant web search results, in programming languages and libraries such as Python, SciPy, Sci-Kit Learn, and data mining.
Real-World applications of K-means Clustering —
- Identifying fake news
- Spam detection and filtering
- Classify books or movies by genre
- Popular transport routes while town planning
Useful links:
8. Support Vector Machines
Support Vector Machines are categorized as supervised machine learning algorithms and are primarily used for classification and regression analysis.
The algorithm works by building models that assign new examples and data to a category, where these categories are easily distinguishable from one another by a gap.
SVM is highly effective in cases where the number of dimensions outweighs the number of samples and is extremely memory-efficient.
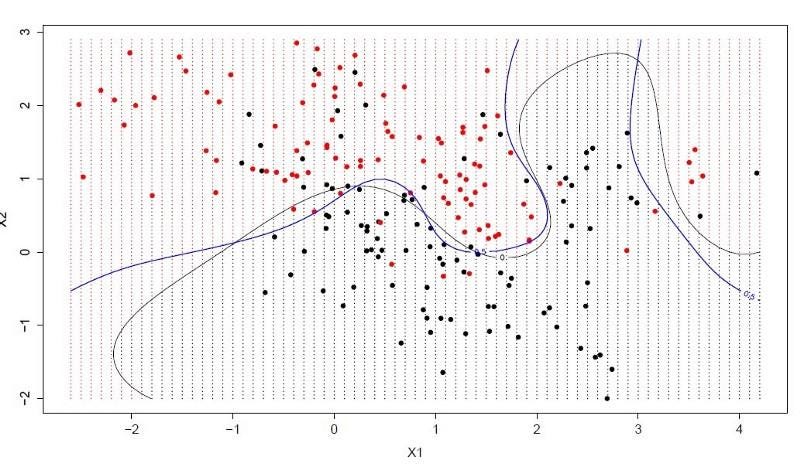
Highly effective Support Vector Machines algorithm(source)
SVM applications can be found in:
- Face Detection
- Image Classification
- Text & Hypertext Categorization
- Handwriting recognition
- Drug Discovery for Therapy
- Bioinformatics — protein, genes, biological, or cancer classification.
Useful links:
9. K-nearest Neighbors
K-nearest neighbors is a supervised ML algorithm used for both regression and classification problems.
Usually implemented for pattern recognition, this algorithm first stores, and identifies the distance between all inputs in the data using a distance function, selects the k specified inputs closest to query and outputs:
- The most frequent label (for classification)
- The average value of k nearest neighbors (for regression)
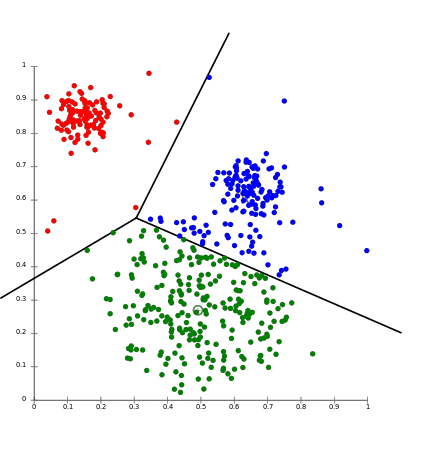
K-nearest Neighbors(source)
Real-life applications of this algorithm include —
- Fingerprint detection
- Credit rating
- Forecasting the stock market
- Analyzing money laundering
- Bank bankruptcies
- Currency exchange rate
10. Dimensionality Reduction Algorithms
Dimensionality Reduction algorithms work by reducing the dimension space or the number of random variables in a dataset by using one of the two primary approaches, Feature Selection or Feature Extraction.
These are often applied to preprocess the datasets, and to remove redundant features, making it easier for algorithms to train the model.
These algorithms also come with a few nifty benefits, such as:
- Low storage requirements
- Less computing power required
- Increased accuracy
- Reduced noise
A few well-known Dimensionality Reduction algorithms are:
- Principal Component Analysis
- Linear Discriminant Analysis
- Locally Linear Embedding
- Multi-dimensional Scaling
11. Principal Component Analysis
Principal Component Analysis is one of the unsupervised algorithms for ML and is primarily used for reducing dimensions of your feature space by using either Feature Elimination or Feature Extraction.
It is also used as a tool for exploratory data analysis and building predictive models. Requiring normalized data, PCA can help with:
- Image Processing
- Movie recommendation system
- Calculating data covariance matrix
- Perform eigenvalue decomposition on the covariance matrix
- Optimize power allocation in multiple communication channels
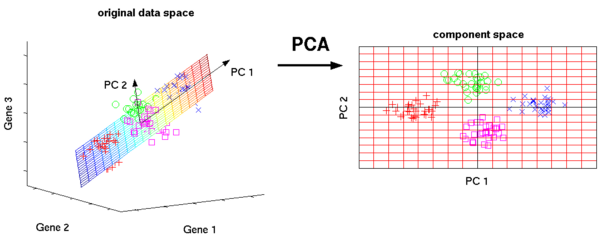
Principal Component Analysis(source)
PCA aims to reduce redundancies from the datasets, making it simpler without compromising on accuracy. It is commonly deployed in image processing and risk management sectors.
Useful links:
12. Random Forests
Random Forests use a variety of algorithms for solving classification, regression, and similar problems by implementing decision trees.
The way it works is, it creates heaps of decision trees with random sets of data, and a model is trained repeatedly on it for near-accurate results.
In the end, all the results from these decision trees are combined to identify the best suitable result that appears most commonly in the output.
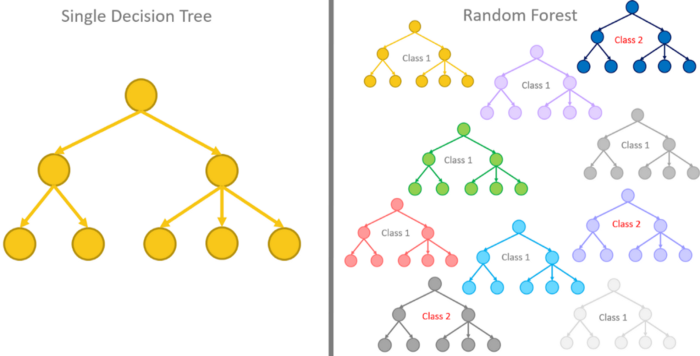
Random forests(source)
Random Forests applications can be found in —
- Fraud detection for bank accounts, credit card
- Detect and predict the drug sensitivity of a medicine
- Identify a patient’s disease by analyzing their medical records
- Predict estimated loss or profit while purchasing a particular stock
13. Gradient Boosting & AdaBoost
Boosting is a technique for ensemble ML algorithms converting weak learners to strong learners. Boosting algorithms are required when data is abundant, and we seek to reduce the bias and variance in supervised learning. Below are two of the popular boosting algorithms.
- Gradient Boosting
Gradient Boosting algorithm is used for classification and regression problems by building a prediction model typically in an iterative manner such as the decision trees. It improves the weak learners by training it on the errors of the strong learners resulting in an overall accurate learner.
- AdaBoost
Short for Adaptive Boosting, AdaBoost improves the model when the weak learners fail. It does so by modifying the weights attached to the instances in the sample to focus more on the hard ones, later, the output from the weak learners is combined to form a weighted sum, and is considered the final boosted output.
Conclusion
ML algorithms are vital for Data Scientists due to their increasing applications in the real world. With a variety of algorithms mentioned above, you can find an algorithm that best solves your problem. These algorithms, albeit being a mix of supervised and unsupervised, can handle a variety of tasks and are capable of working in sync with other algorithms.
Further Sources —
I hope you’ve found this article useful! Below are additional resources if you’re interested in learning more: —
About Author
Claire D. is a Content Crafter and Marketer at Digitalogy — a tech sourcing and custom matchmaking marketplace that connects people with pre-screened & top-notch developers and designers based on their specific needs across the globe. Connect with Digitalogy on Linkedin, Twitter, Instagram.








