Data Science
Tournaments
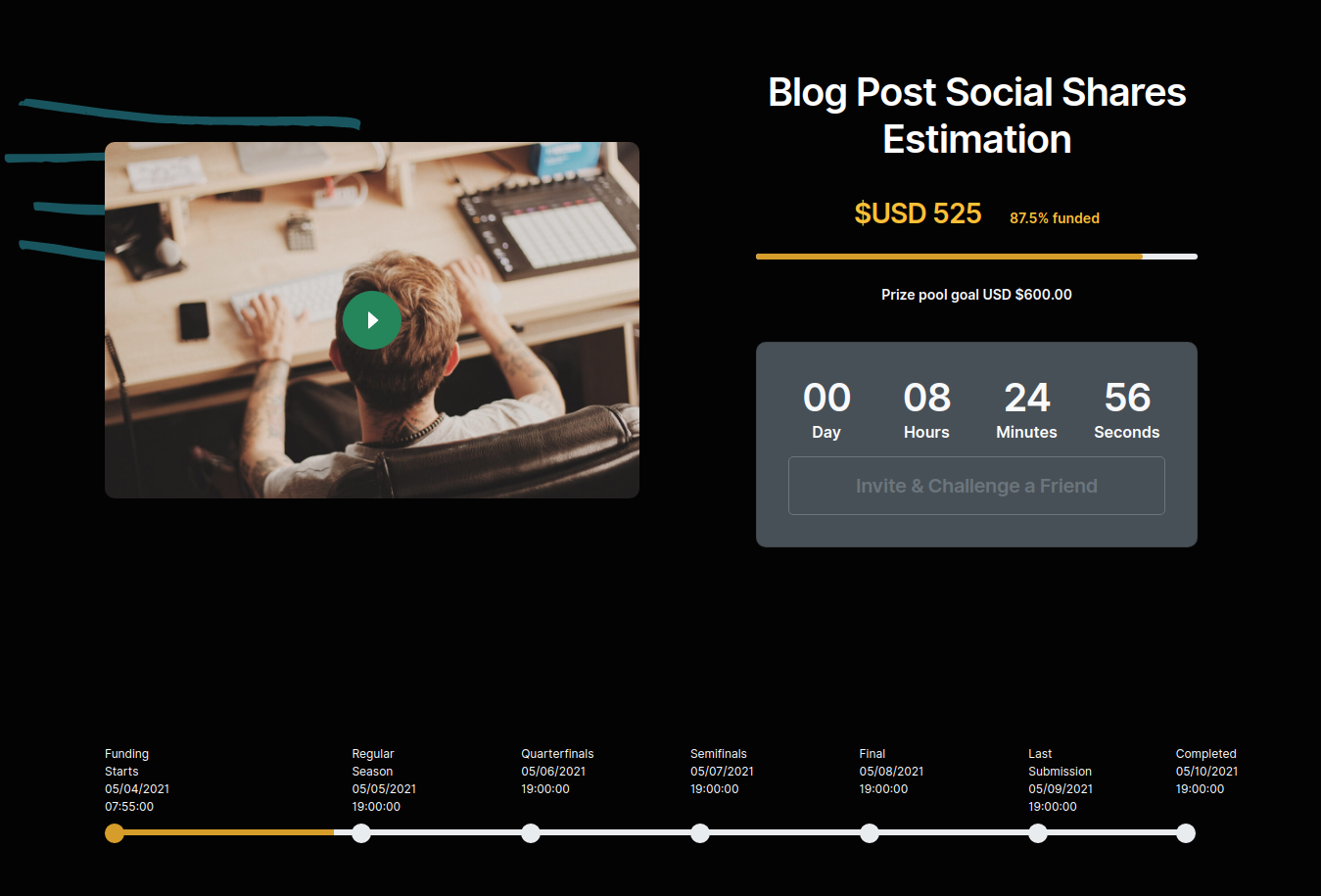
It’s a community-funded data science tournament, where the competition is decided by playoffs, best scores win the pool prize, and everybody receives the winning' ML models. Test your competitive spirit, your love of data science, and enjoy the adrenaline rush as you prove (and enhance) your data skills.
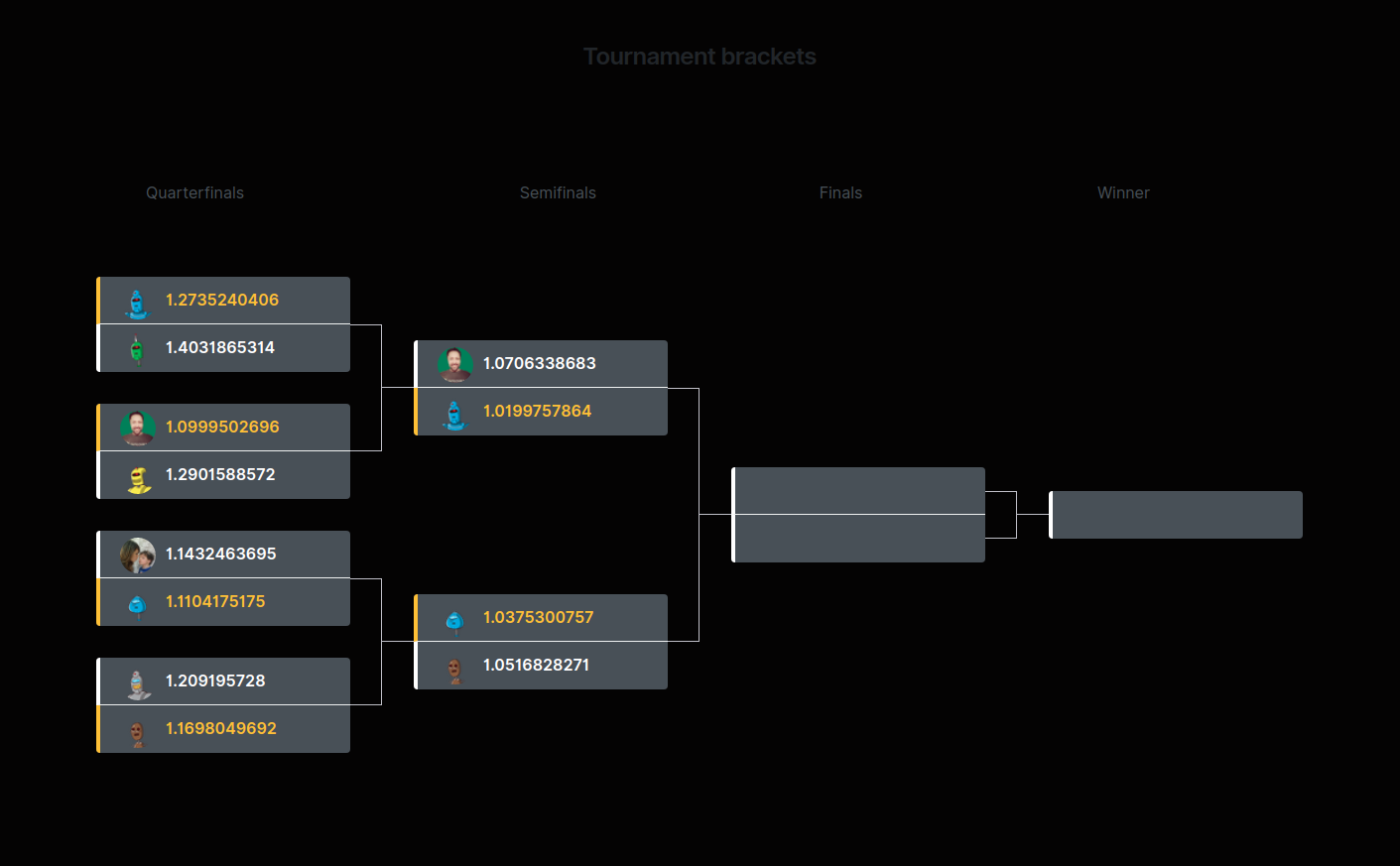
Tournament Brackets
 3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
Quaterfinals
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
3.2248868699715714
Semifinals
3.2248868699715714
3.2248868699715714
Finals
3.2248868699715714
3.2248868699715714
3.2248868699715714
Winner










 Funding Stage
Funding Stage
 Regular season
Regular season
 Quarterfinals
Quarterfinals