
Apache Spark vs. Hadoop MapReduce — pros, cons, and when to use which

What is Apache Spark?
The company founded by the creators of Spark — Databricks — summarizes its functionality best in their Gentle Intro to Apache Spark eBook (highly recommended read - link to PDF download provided at the end of this article):
“Apache Spark is a unified computing engine and a set of libraries for parallel data processing on computer clusters. As of the time of this writing, Spark is the most actively developed open source engine for this task; making it the de facto tool for any developer or data scientist interested in Big Data. Spark supports multiple widely used programming languages (Python, Java, Scala, and R), includes libraries for diverse tasks ranging from SQL to streaming and machine learning, and runs anywhere from a laptop to a cluster of thousands of servers. This makes it an easy system to start with and scale up to Big Data processing on an incredibly large scale.”
What is Big Data?
Let’s look at Gartner’s widely used definition of Big Data, so we can later understand how Spark opts to tackle lots of the challenges associated with working with Big Data in real-time at scale:
“Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.”

The Complex World of Big Data
Note: The key takeaway here is that the “Big” in Big Data is not just about volume. You’re not just getting a lot of data, but it is also coming at you fast in real-time, in a complex format, and from a variety of sources. Hence the 3-Vs of Big Data - Volume, Velocity, Variety.
Why do most Big Data Analytics companies get a “spark in their eye” when they hear about all of Spark’s useful functionalities?
Based on my preliminary research, it seems there are three main components that make Apache Spark the leader in working efficiently with Big Data at scale, which motivate a lot of big companies working with large amounts of unstructured data, to adopt Apache Spark into their stack.
-
Spark is a unified, one-stop-shop for working with Big Data — “Spark is designed to support a wide range of data analytics tasks, ranging from simple data loading and SQL queries to machine learning and streaming computation, over the same computing engine and with a consistent set of APIs. The main insight behind this goal is that real-world data analytics tasks — whether they are interactive analytics in a tool, such as a Jupyter notebook, or traditional software development for production applications — tend to combine many different processing types and libraries. Spark’s unified nature makes these tasks both easier and more efficient to write” (Databricks eBook). For example, if you load data using a SQL query and then evaluate a machine learning model over it using Spark’s ML library, the engine can combine these steps into one scan over the data. Furthermore, Data Scientists can benefit from a unified set of libraries (e.g., Python or R) when doing modeling, and Web Developers can benefit from unified frameworks such as Node.js or Django.
-
Spark optimizes its core engine for computational efficiency — “by this, we mean that Spark only handles loading data from storage systems and performing computation on it, not permanent storage as the end itself. Spark can be used with a wide variety of persistent storage systems, including cloud storage systems such as Azure Storage and Amazon S3, distributed file systems such as Apache Hadoop, key-value stores such as Apache Cassandra, and message buses such as Apache Kafka. However, Spark neither stores data long-term itself nor favors one of these. The key motivation here is that most data already resides in a mix of storage systems. Data is expensive to move so Spark focuses on performing computations over the data, no matter where it resides” (Databricks eBook). Spark’s focus on computation makes it different from earlier big data software platforms such as Apache Hadoop. Hadoop included both a storage system (the Hadoop file system, designed for low-cost storage over clusters of Defining Spark 4 commodity servers) and a computing system (MapReduce), which were closely integrated together. However, this choice makes it hard to run one of the systems without the other, or more importantly, to write applications that access data stored anywhere else. While Spark runs well on Hadoop storage, it is now also used broadly in environments where the Hadoop architecture does not make sense, such as the public cloud (where storage can be purchased separately from computing) or streaming applications.
- Spark’s libraries give it a very wide range of functionalities — Today, Spark’s standard libraries are the bulk of the open source project. The Spark core engine itself has changed little since it was first released, but the libraries have grown to provide more and more types of functionality, turning it into a multifunctional data analytics tool. Spark includes libraries for SQL and structured data (Spark SQL), machine learning (MLlib), stream processing (Spark Streaming and the newer Structured Streaming), and graph analytics (GraphX). Beyond these libraries, there are hundreds of open source external libraries ranging from connectors for various storage systems to machine learning algorithms.
Apache Spark vs. Hadoop MapReduce…Which one should you use?
The short answer is — it depends on the particular needs of your business, but based on my research, it seems like 7 out of 10 times the answer will be — Spark. Linear processing of huge datasets is the advantage of Hadoop MapReduce, while Spark delivers fast performance, iterative processing,real-time analytics, graph processing, machine learning and more.
The great news is that Spark is fully compatible with the Hadoop eco-system and works smoothly with Hadoop Distributed File System (HDFS), Apache Hive, and others. So, when the size of the data is too big for Spark to handle in memory, Hadoop can help overcome that hurdle via its HDFS functionality. Below is a visual example of how Spark and Hadoop can work together:
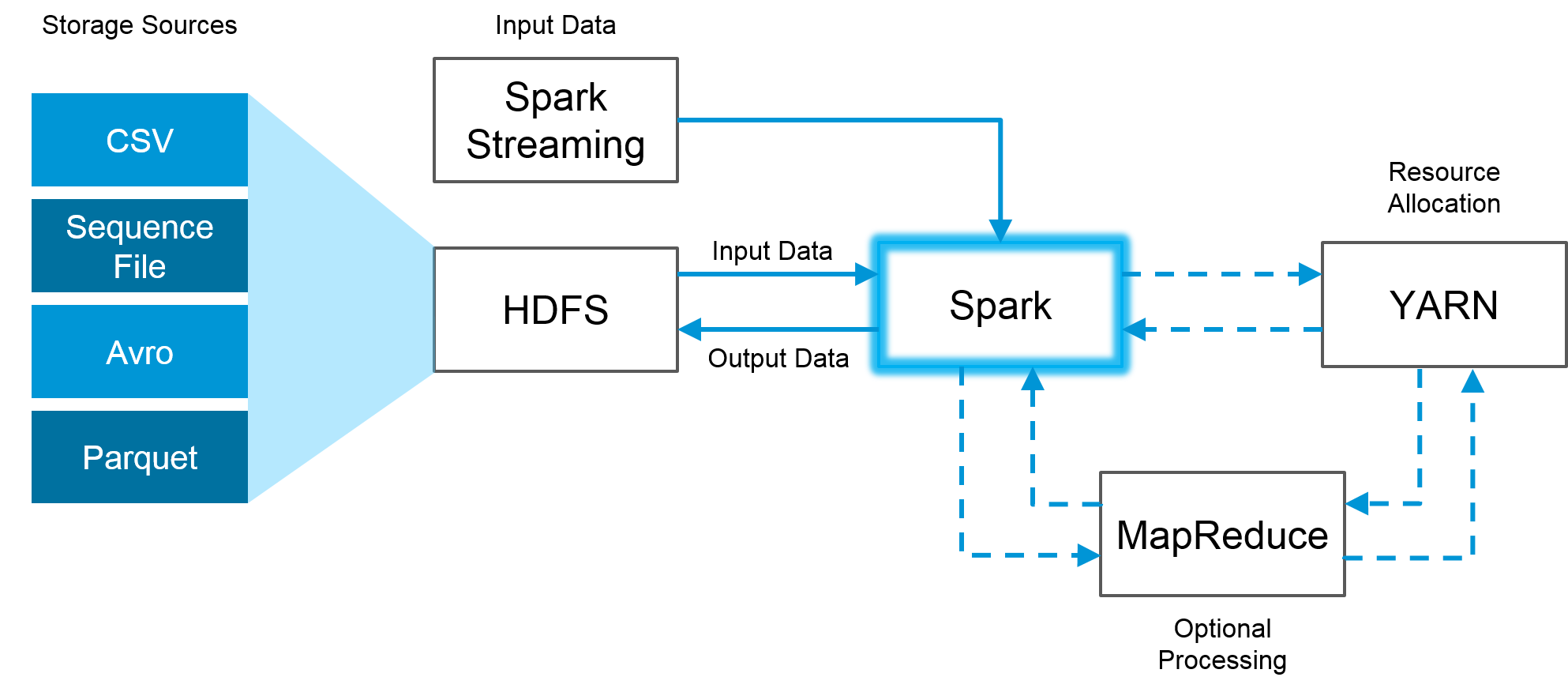
The image above demonstrates how Spark uses the best parts of Hadoop through HDFS for reading and storing data, MapReduce for optional processing and YARN for resource allocation.
Next, I will try to highlight Spark’s many advantages over Hadoop MapReduce by performing a brief head-to-head comparison between the two.

Speed
- Apache Spark — it’s a lightning-fast cluster computing tool. Spark runs applications up to 100x faster in memory and 10x faster on disk than Hadoop by reducing the number of read-write cycles to disk and storing intermediate data in-memory.
- Hadoop MapReduce — MapReduce reads and writes from disk, which slows down the processing speed and overall efficiency.
Ease of Use
- Apache Spark — Spark’s many libraries facilitate the execution of lots of major high-level operators with RDD (Resilient Distributed Dataset).
- Hadoop — In MapReduce, developers need to hand-code every operation, which can make it more difficult to use for complex projects at scale.
Handling Large Sets of Data
- Apache Spark — since Spark is optimized for speed and computational efficiency by storing most of the data in memory and not on disk, it can underperform Hadoop MapReduce when the size of the data becomes so large that insufficient RAM becomes an issue.
- Hadoop — Hadoop MapReduce allows parallel processing of huge amounts of data. It breaks a large chunk into smaller ones to be processed separately on different data nodes. In case the resulting dataset is larger than available RAM, Hadoop MapReduce may outperform Spark. It’s a good solution if the speed of processing is not critical and tasks can be left running overnight to generate results in the morning.
Functionality
Apache Spark is the uncontested winner in this category. Below is a list of the many Big Data Analytics tasks where Spark outperforms Hadoop:
- Iterative processing. If the task is to process data again and again — Spark defeats Hadoop MapReduce. Spark’s Resilient Distributed Datasets (RDDs) enable multiple map operations in memory, while Hadoop MapReduce has to write interim results to a disk.
- Near real-time processing. If a business needs immediate insights, then they should opt for Spark and its in-memory processing.
- Graph processing. Spark’s computational model is good for iterative computations that are typical in graph processing. And Apache Spark has GraphX — an API for graph computation.
- Machine learning. Spark has MLlib — a built-in machine learning library, while Hadoop needs a third-party to provide it. MLlib has out-of-the-box algorithms that also run in memory.
- Joining datasets. Due to its speed, Spark can create all combinations faster, though Hadoop may be better if joining very large data sets that require a lot of shuffling and sorting is needed.
A visual summary of Spark’s many capabilities and its compatibility with other Big Data engines and programming languages below:
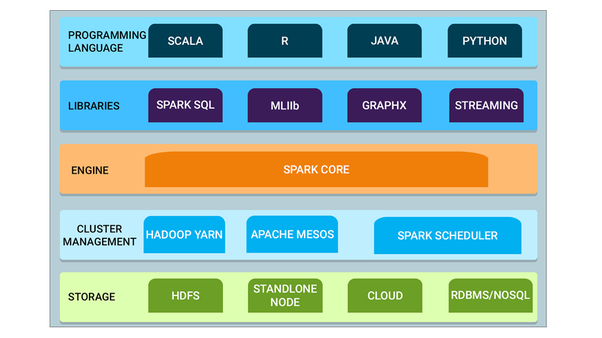
-
Spark Core — Spark Core is the base engine for large-scale parallel and distributed data processing. Further, additional libraries which are built on top of the core allow diverse workloads for streaming, SQL, and machine learning. It is responsible for memory management and fault recovery, scheduling, distributing and monitoring jobs on a cluster & interacting with storage systems.
-
Cluster management — A cluster manager is used to acquire cluster resources for executing jobs. Spark core runs over diverse cluster managers including Hadoop YARN, Apache Mesos, Amazon EC2 and Spark’s built-in cluster manager. The cluster manager handles resource sharing between Spark applications. On the other hand, Spark can access data in HDFS, Cassandra, HBase, Hive, Alluxio, and any Hadoop data source
-
Spark Streaming — Spark Streaming is the component of Spark which is used to process real-time streaming data.
-
Spark SQL: Spark SQL is a new module in Spark which integrates relational processing with Spark’s functional programming API. It supports querying data either via SQL or via the Hive Query Language. The DataFrame and Dataset APIs of Spark SQL provide a higher level of abstraction for structured data.
-
GraphX: GraphX is the Spark API for graphs and graph-parallel computation. Thus, it extends the Spark RDD with a Resilient Distributed Property Graph.
- MLlib (Machine Learning): MLlib stands for Machine Learning Library. Spark MLlib is used to perform machine learning in Apache Spark.
Conclusion
With the massive explosion of Big Data and the exponentially increasing speed of computational power, tools like Apache Spark and other Big Data Analytics engines will soon be indispensable to Data Scientists and will quickly become the industry standard for performing Big Data Analytics and solving complex business problems at scale in real-time. For those interested in diving deeper into the technology behind all those functionalities, please click on the link below and download Databricks’s eBook — “A Gentle Intro to Apache Spark”, or check out “Big Data Analytics on Apache Spark”.









